


MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,Hadoop MapReduce提供了一个易于编程的框架,该框架可在大型集群(上千节点)上可靠、容错地快速处理大量数据,下面将详细解析MapReduce的基本原理,并使用小标题和单元表格来清晰地展示其核心概念:
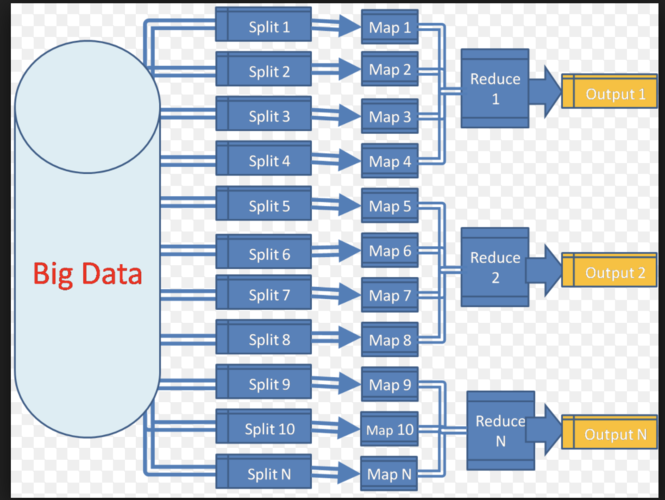

1、MapReduce
概念理解:MapReduce是一个编程模型,分为两个基本操作——Map和Reduce,它允许开发人员编写业务逻辑代码,与Hadoop自带组件整合,形成完整的分布式运算程序。
数据处理流程:Map负责数据的映射和过滤,而Reduce负责数据的聚合和归纳,这两个过程合作完成大数据的处理任务。
2、Map函数详解
映射过程:在Map阶段,输入数据被拆分成小块,每块分别进行Map函数处理,Map函数通常用来执行数据变换,比如数据清洗或转换格式。
过滤功能:Map函数除了进行数据变换外,还负责数据的初步筛选,过滤掉不必要的信息,只保留符合要求的数据项。
3、Reduce函数详解
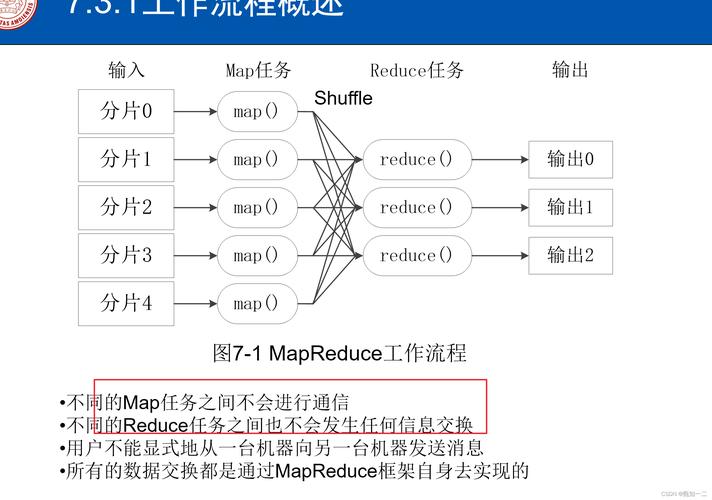
聚合过程:经过Map处理的数据项,会通过Shuffle过程传递给Reduce,Reduce函数接着对数据进行汇总,例如统计相同键值的数据项数量或进行其他形式的聚合操作。
归纳归纳:Reduce将处理结果输出,这个结果往往是更精炼的数据集或是基于原始数据集合的最终计算结果。
4、MapReduce工作流程
分而治之的策略:MapReduce采用“分而治之”的策略,先将大数据集切分成小块,分别处理(Map),再将中间结果合并得到最终结果(Reduce)。
并行化处理:MapReduce框架能够自动并行处理多个Map和Reduce任务,从而显著提高大规模数据处理的速度。
5、数据流和控制流
数据流:MapReduce作业的数据流从输入数据开始,经过Map处理,通过Shuffle排序,最终进入Reduce处理,生成输出结果。
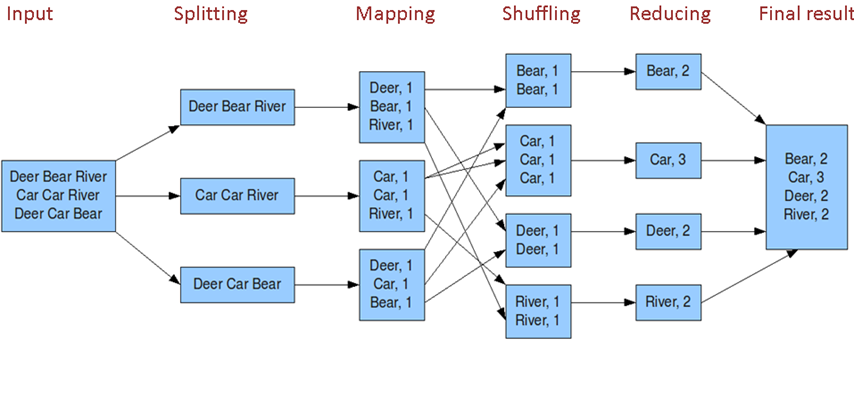
控制流:控制流描述了作业的调度和监控过程,包括作业提交、状态跟踪和错误处理等。
6、容错性和可靠性
容错机制:MapReduce框架设计了健壮的容错机制,能够自动重新执行失败的Map或Reduce任务。
数据备份:系统会默认对数据进行备份,以防数据丢失导致的任务失败。
7、适用场景与优势
适用场景:MapReduce适用于批量处理大规模数据集,如日志分析、数据挖掘等场景。
性能优势:由于并行处理的特性,MapReduce能够在数分钟内处理TB级别的数据,相比传统数据库处理方法大大节省了时间成本。
8、实际应用中的优化技巧
代码优化:合理设计Map和Reduce函数可以提升数据处理效率,减少不必要的数据移动和复制。
配置调整:根据集群的特点和作业的需求,调整Hadoop配置参数,如内存分配、并发任务数量等,可以进一步优化性能。
随着对MapReduce原理的深入理解,还需注意以下几点以更好地应用于实践:
确保在设计Map和Reduce函数时充分考虑数据的局部性,以减少网络传输开销。
适当地设置数据块大小和备份数量,以平衡存储成本和容错需求。
监控和调试工具对于定位问题和优化作业性能至关重要,不要忽视它们的作用。
MapReduce作为一个高效的数据处理模型,其强大的并行处理能力和容错机制使它成为大数据分析领域的核心工具,掌握其基本原理及优化技巧对于从事相关领域的专业人士至关重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/830419.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复