


MapReduce是一种编程模型,用于处理和生成大数据集。它包括两个主要阶段:Map和Reduce。在Map阶段,输入数据被分成小块并分配给不同的节点进行处理;在Reduce阶段,各个节点处理的结果被汇总并输出最终结果。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要步骤组成:Map(映射)和Reduce(归约),以下是MapReduce过程的详细实现过程:

(图片来源网络,侵删)
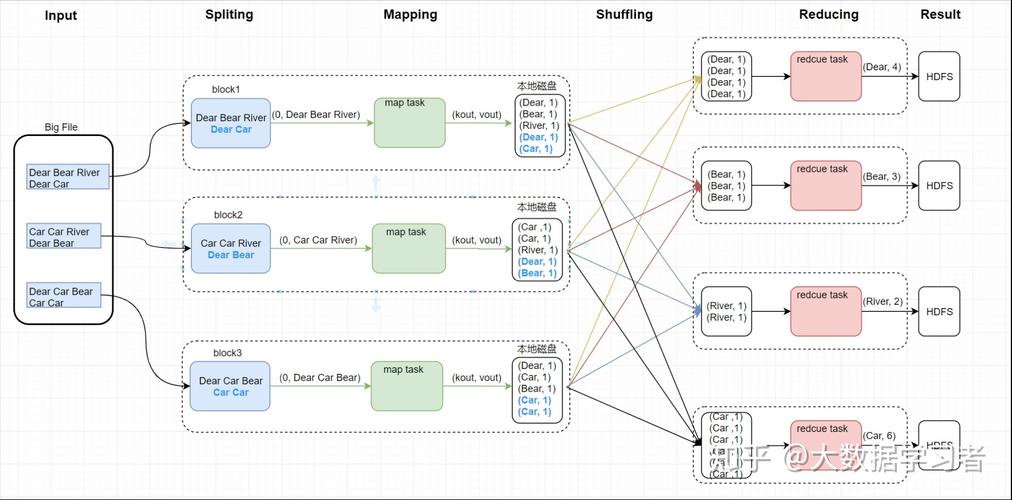
1、Map阶段
输入数据被分割成多个独立的块。
每个块被分配给一个Map任务。
Map任务读取输入数据块,并对每个记录应用map函数。
map函数将输入数据转换为一组键值对(keyvalue pairs)。
Map任务输出中间结果,即键值对集合。
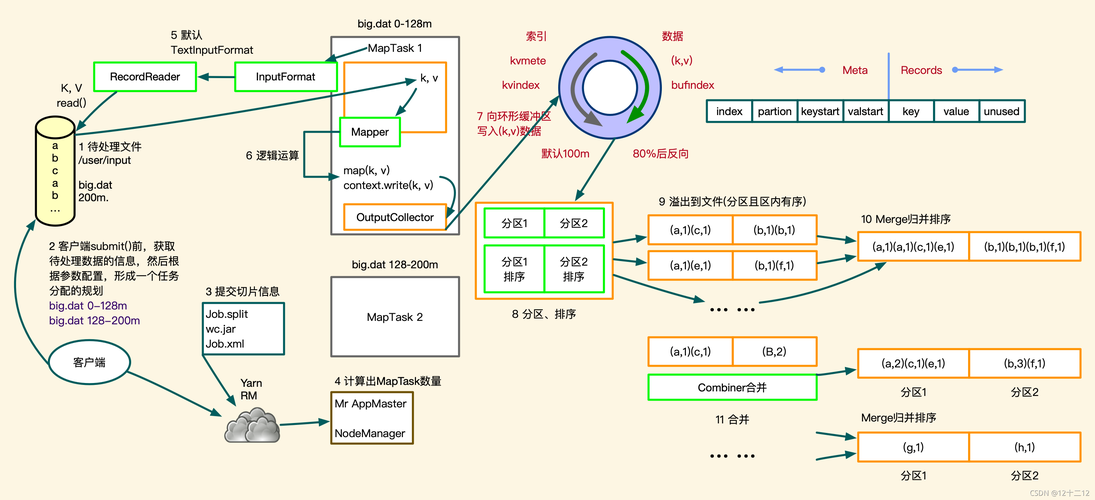
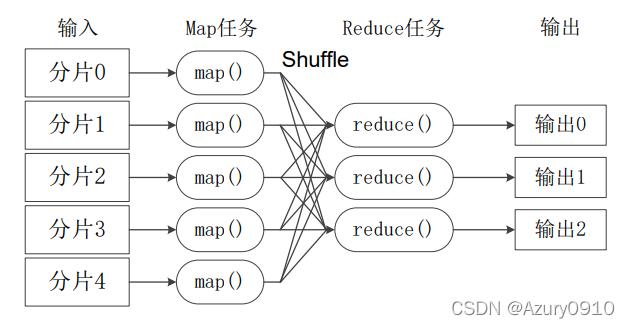
2、Shuffle阶段
(图片来源网络,侵删)
系统将所有Map任务的输出收集起来。
根据键值对中的键进行排序。
相同的键会被分组在一起,形成一个新的键值对列表。
3、Reduce阶段
系统为每个唯一的键创建一个Reduce任务。
Reduce任务接收相同键的所有值作为输入。
Reduce函数对这些值进行处理,并产生单个输出值。
(图片来源网络,侵删)
Reduce任务输出最终结果。
4、输出阶段
Reduce任务的输出被汇总并写入到最终的结果文件中。
下面是一个简单的MapReduce示例,用于计算文本中单词的出现次数:
Map函数
def map_function(text):
words = text.split()
return [(word, 1) for word in words]
Reduce函数
def reduce_function(key, values):
return (key, sum(values))
假设我们有一个包含多行文本的文件"input.txt"
with open("input.txt", "r") as file:
lines = file.readlines()
Map阶段
mapped_results = []
for line in lines:
mapped_results.extend(map_function(line))
Shuffle阶段
shuffled_results = {}
for key, value in mapped_results:
if key not in shuffled_results:
shuffled_results[key] = []
shuffled_results[key].append(value)
Reduce阶段
reduced_results = []
for key, values in shuffled_results.items():
reduced_results.append(reduce_function(key, values))
输出阶段
print(reduced_results)
在这个示例中,map_function将每行文本分割成单词,并为每个单词生成一个键值对(单词,1)。reduce_function将所有相同单词的值相加,得到每个单词的总出现次数,输出结果是一个包含单词及其出现次数的列表。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/829854.html
 微信扫一扫
微信扫一扫