


MapReduce是一个编程模型,用于大规模数据集(大于1TB)的并行运算,其基本思想是将问题的解决分解为两个阶段:Map阶段和Reduce阶段,下面将深入探讨MongoDB中MapReduce的基本原理:
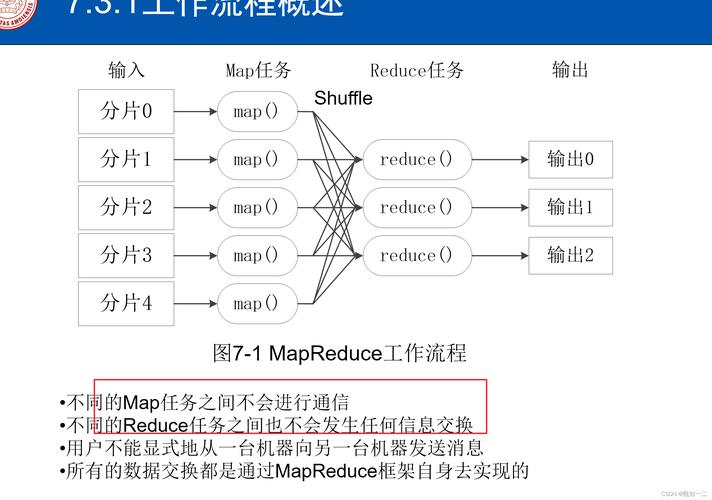

1、MapReduce的基本概念
Map阶段:Map阶段的任务是处理原始数据,将输入的数据项转化为键值对(KeyValue Pair),在此阶段,原始数据被拆分成小数据块,Map函数对这些数据块中的每个项目独立进行处理。
Reduce阶段:Reduce阶段的任务是接收Map阶段生成的中间键值对,并依据键(Key)来汇总值(Value),得出最终结果,在这一过程中通常涉及数据的合并操作。
Shuffle阶段:虽然在MapReduce的概念中不经常明确提到,Shuffle是将Map阶段的输出传送到Reduce阶段的中间过程,负责数据的分组和排序,确保Reduce能够接收到相同键的所有值。
2、Mapper端的操作
数据处理:Mapper分析输入文档,并将每个文档转换为一个或多个键值对。
数据组织:转换得到的键值对会被临时存储,等待进入下一阶段,Mapper端的输出是按照键进行排序的,为Reducer端的聚合操作做准备。
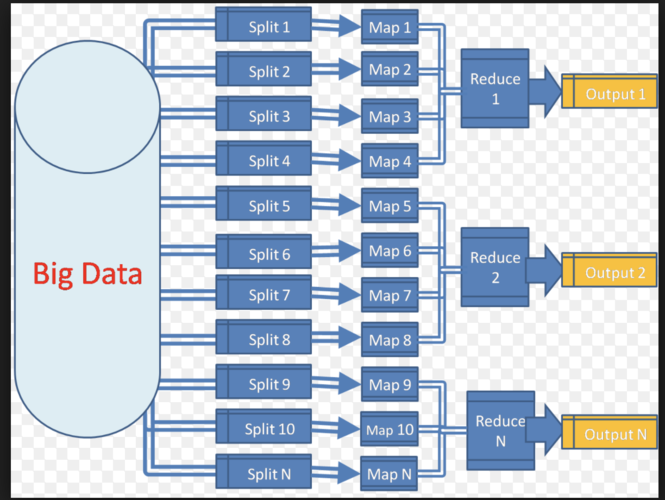
3、Reducer端的操作
结果统计:Reducer获取来自Mapper的输出,对具有相同键的值进行迭代处理,执行求和、平均值计算等最终的统计工作。
数据输出:最终的结果会输出到用户指定的输出集合中,Reducer端的输出格式通常是由用户定义的。
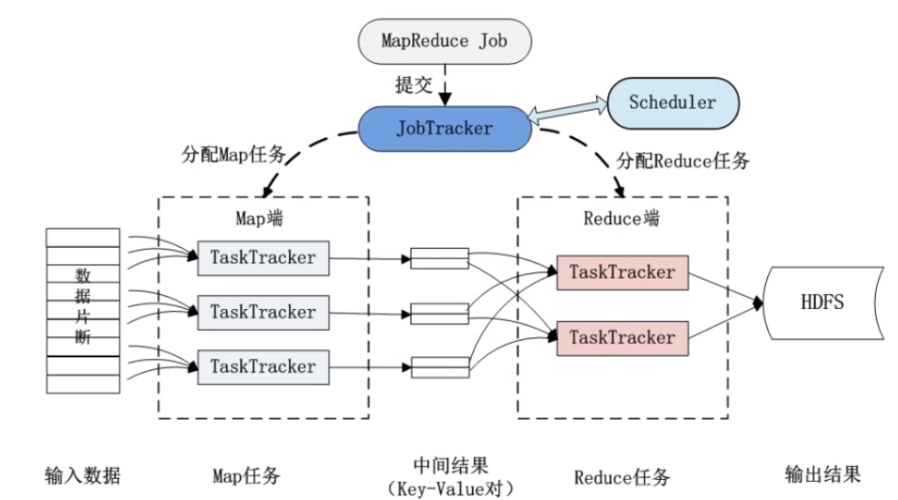
4、MapReduce的工作机制
分布式处理:MapReduce通过在集群中的不同节点上并行执行Mapper和Reducer任务,实现高效的数据处理和分析。
容错性:MapReduce架构设计具有高容错性,即使单个节点失败,整个作业也不会受到影响,可以自动在其他节点上重新执行失败的任务。
5、MapReduce与Aggregation的区别
适用场景:虽然MapReduce和聚合(Aggregation)都可用于数据分析,但MapReduce适合进行更复杂的计算,而聚合框架更适合实时的简单聚合操作。
性能考量:在性能敏感的应用场景中,推荐使用聚合框架,因为它使用了MongoDB的内嵌优化,而MapReduce则适用于后台大批量数据处理。
6、客户端的角色
作业提交:客户端负责提交MapReduce作业,编写Map和Reduce函数,并指定输入输出集合及其他参数。
结果获取:客户端从输出集合中获取最终的统计结果,用于进一步的数据分析或展示。
7、MapReduce的优势与限制
优势:支持大规模分布式计算,隐藏了并行化和分布式处理的复杂性,用户只需关注Map和Reduce函数的实现。
限制:相对于其他数据处理方式,例如聚合框架,MapReduce的性能可能较低,特别是在需要实时响应的系统中。
8、实际应用中的考虑因素
资源利用:在执行MapReduce作业时,合理分配计算资源和内存资源,避免因资源瓶颈影响性能。
数据倾斜问题:注意MapReduce作业中可能出现的数据倾斜问题,即某个Reducer处理的数据远多于其他Reducer,导致该节点成为性能瓶颈。
可以看出MapReduce是一种强大的工具,特别适用于在MongoDB上执行复杂的数据分析任务,尽管在许多现代应用场景中,聚合框架由于其实时性质和性能优势而被优先选择,但在需要深度数据分析且实时性要求不高的情况下,MapReduce仍然是一个宝贵的工具。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/829752.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复