


javax.naming.Context 是 Java Naming and Directory Interface (JNDI) API 的一部分,它提供了一种用于访问命名和目录服务的通用接口,在 MapReduce 中,Context 类通常用于获取配置信息、创建文件系统实例等。
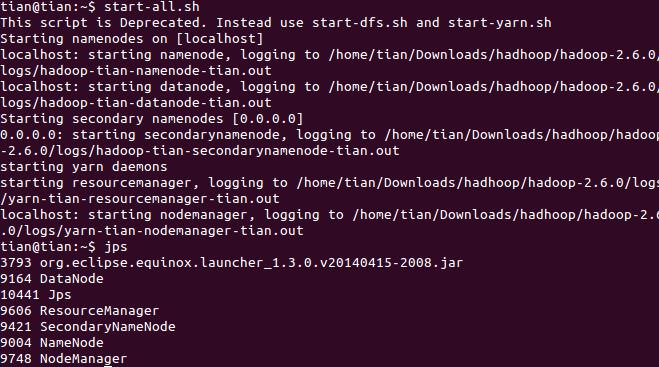

以下是关于javax.naming.Context 的一些详细信息:
1.
javax.naming.Context 是一个抽象类,它定义了一组用于访问命名和目录服务的方法,这些方法包括查找、绑定、解除绑定、重命名、列表等,具体的实现类(如InitialContext)会根据底层的命名和目录服务提供相应的实现。
2. 使用场景
在 MapReduce 中,Context 类主要用于以下场景:
获取 Hadoop 配置信息,HDFS 路径、任务数量等。
创建文件系统实例,以便在 MapReduce 任务中读写数据。
获取其他资源,如数据库连接池、缓存等。
3. 示例代码
以下是一个简单的示例,展示了如何在 MapReduce 中使用Context 类获取配置信息和创建文件系统实例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
public class MyMapReduceJob {
public static void main(String[] args) throws Exception {
// 创建 Job 配置对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("mapreduce.job.reduces", "2");
// 创建 Job 实例
Job job = Job.getInstance(conf, "My MapReduce Job");
// 获取 Context 实例
Context context = new InitialContext();
// 从 Context 获取配置信息
String defaultFS = context.lookup("fs.defaultFS");
int numReducers = Integer.parseInt(context.lookup("mapreduce.job.reduces"));
// 输出配置信息
System.out.println("Default FileSystem: " + defaultFS);
System.out.println("Number of reducers: " + numReducers);
// 创建 FileSystem 实例
FileSystem fs = FileSystem.get(conf);
// 使用 FileSystem 实例操作 HDFS
Path inputPath = new Path("/user/input");
Path outputPath = new Path("/user/output");
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
fs.mkdirs(outputPath);
}
} 在这个示例中,我们首先创建了一个Configuration 对象,并设置了 HDFS 的默认文件系统和 reducer 的数量,我们创建了一个Job 实例,并使用InitialContext 类获取了一个Context 实例,我们从Context 中获取了一些配置信息,并创建了一个FileSystem 实例,我们使用FileSystem 实例操作 HDFS,例如检查输出路径是否存在并删除它,然后创建一个新的输出目录。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/828887.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复