


Maven MapReduce 例子
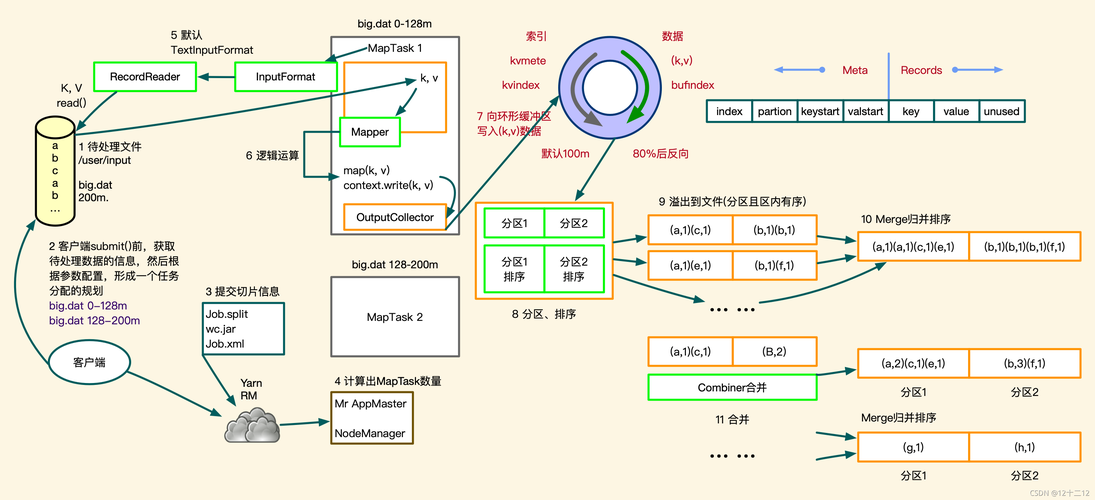

Maven是一个强大的项目管理工具,它可以帮助我们构建、测试和部署Java项目,下面是一个使用Maven构建MapReduce程序的例子。
1. 创建Maven项目
我们需要创建一个Maven项目,可以使用以下命令在命令行中创建一个新的Maven项目:
mvn archetype:generate DgroupId=com.example DartifactId=mapreduceexample DarchetypeArtifactId=mavenarchetypequickstart DinteractiveMode=false
这将创建一个名为mapreduceexample的新项目,其groupId为com.example。
2. 添加依赖
我们需要添加Hadoop MapReduce的依赖到项目的pom.xml文件中,在<dependencies>标签内添加以下内容:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoopcommon</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoopmapreduceclientcore</artifactId>
<version>3.3.1</version>
</dependency> 这里的版本号可能会随着时间推移而发生变化,请根据实际情况选择合适的版本。
3. 编写MapReduce程序
现在我们可以开始编写一个简单的MapReduce程序,在src/main/java/com/example目录下创建一个名为WordCount.java的文件,并添加以下代码:
package com.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 这个程序实现了一个简单的单词计数功能,它将输入文本中的每个单词映射到一个键值对(单词,1),然后通过Reducer将所有相同单词的值相加,得到每个单词的总计数。
4. 编译和运行程序
在项目根目录下,运行以下命令来编译和打包项目:
mvn clean package
这将生成一个名为mapreduceexample1.0SNAPSHOT.jar的JAR文件,我们需要将这个JAR文件提交给Hadoop集群进行运行,假设我们已经配置好了Hadoop集群,可以使用以下命令运行程序:
hadoop jar target/mapreduceexample1.0SNAPSHOT.jar com.example.WordCount /input /output
/input是HDFS上存储输入数据的路径,/output是HDFS上存储输出结果的路径。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/828485.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复