


MapReduce思想是分布式计算中的一种编程模型,用于大规模数据集(大于1TB)的并行运算,这一模型通过将计算过程分解为两个阶段—Map阶段和Reduce阶段—来实现高效的数据处理,下面将详细介绍MapReduce的基本原理:
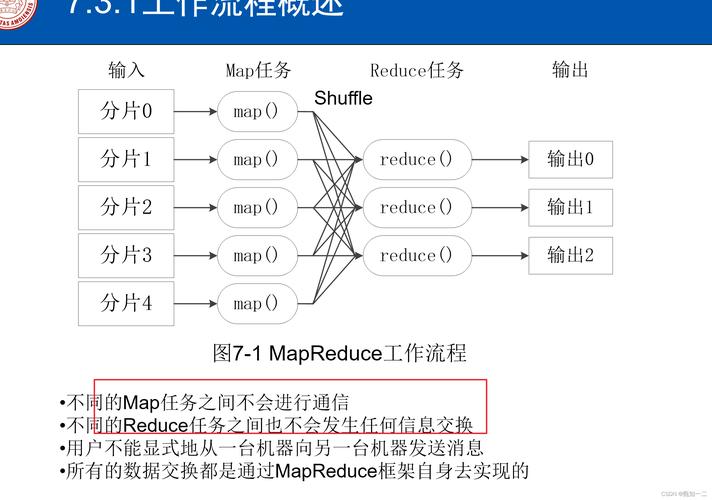

一、Map阶段的工作原理
1、数据分割与处理
输入数据:Map阶段的输入是原始数据,通常存储在分布式文件系统(如HDFS)中。
数据分割:MapReduce自动将输入数据分割成小数据块,每个数据块由一个Map任务处理。
键值对提取:每个数据记录转换为键值对形式。
2、映射处理
映射函数:用户自定义的Map函数接收输入的键值对,进行处理后生成一组中间键值对。
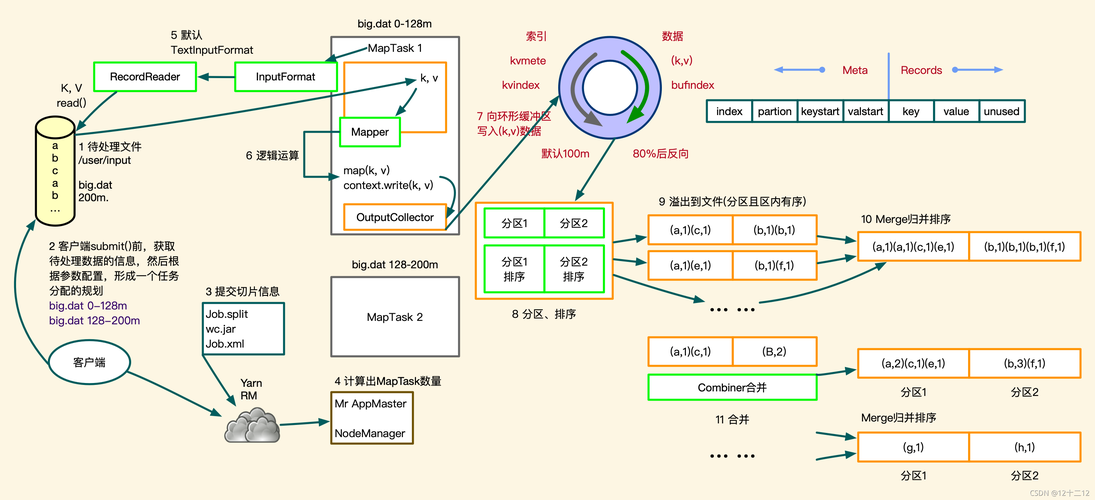
过滤与变换:Map函数主要进行数据的过滤、变换等操作,以适应后续处理需求。
输出:Map函数的输出是一系列新的键值对,准备供Reduce阶段使用。
3、数据排序与传输
本地排序:输出的键值对会被在本地进行排序。
数据传输:排序后的数据会根据键值被分发到各个Reduce节点。
二、Reduce阶段的工作原理
1、数据整合
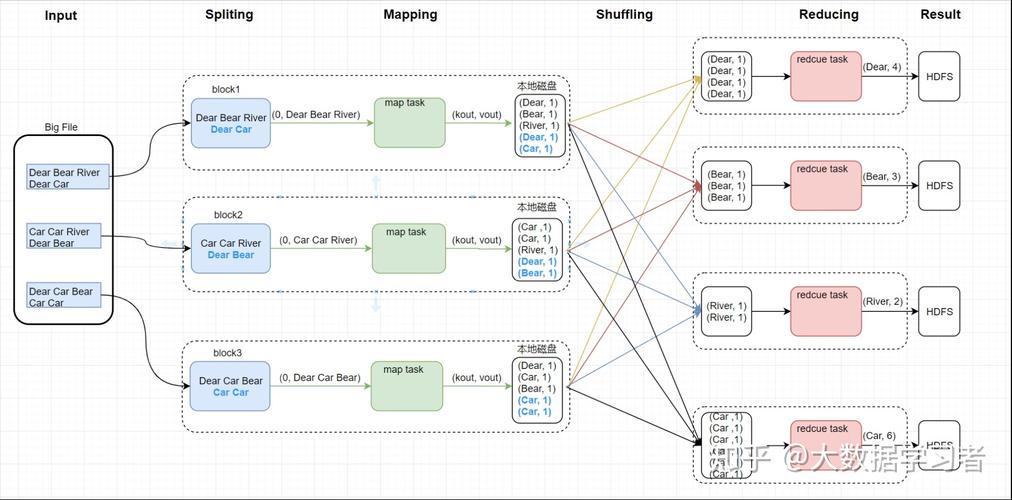
汇总:Reduce节点接收到的具有相同键值的数据将被汇总在一起。
处理:用户自定义的Reduce函数将对汇总后的数据进行处理,生成最终结果。
输出:处理结果将被写回到分布式文件系统中。
2、容错性与可靠性
任务失败处理:MapReduce框架能够检测失败的任务并重新执行。
数据备份:为了提高可靠性,输入数据通常会有备份。
系统扩展性:Reduce阶段的设计允许系统容易地扩展至大规模集群。
MapReduce模型通过显著简化分布式程序设计,使得开发人员可以容易地处理海量数据,由于其高容错性和可扩展性,MapReduce成为了大数据处理的核心技术之一。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/828283.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复