


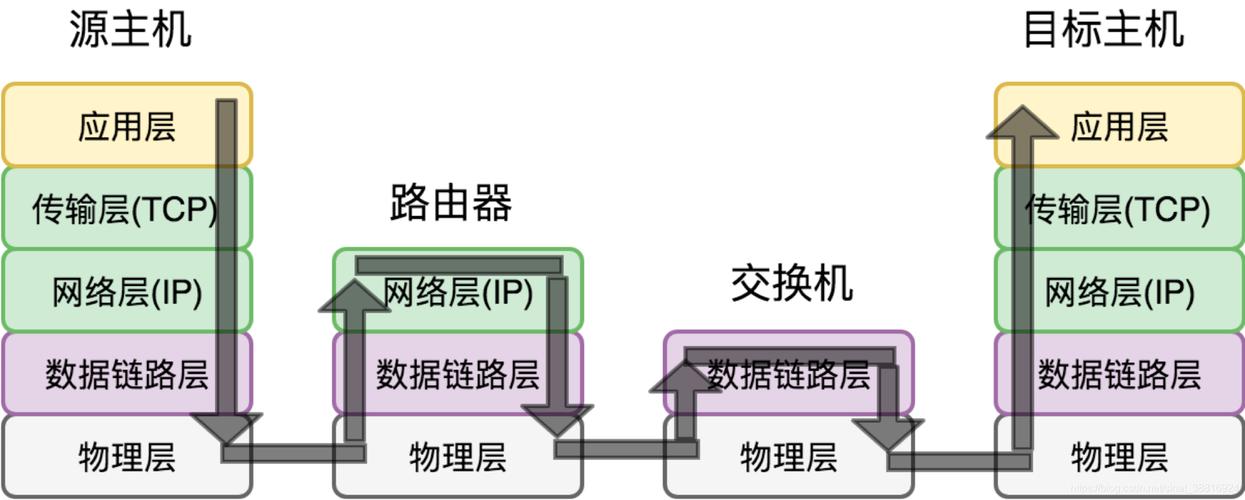
MapReduce数据传输机制

深入解析数据处理核心组件
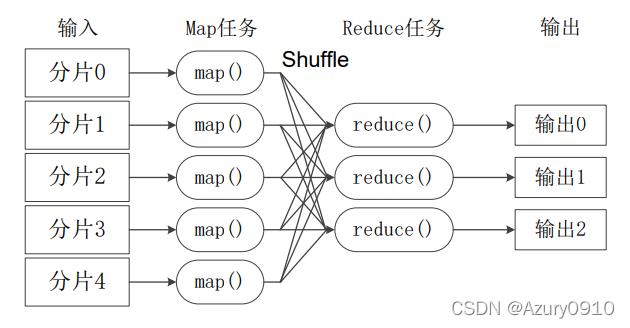
1、MapReduce框架
数据分割与处理流程
Map和Reduce阶段作用
分布式实现优势
2、Map阶段数据传输
输入数据分块机制
键值对生成过程
数据向Reduce传递
3、Reduce阶段数据传输
聚合操作执行
自定义Partitioner控制
最终结果生成方式
4、Copy与Merge阶段详解
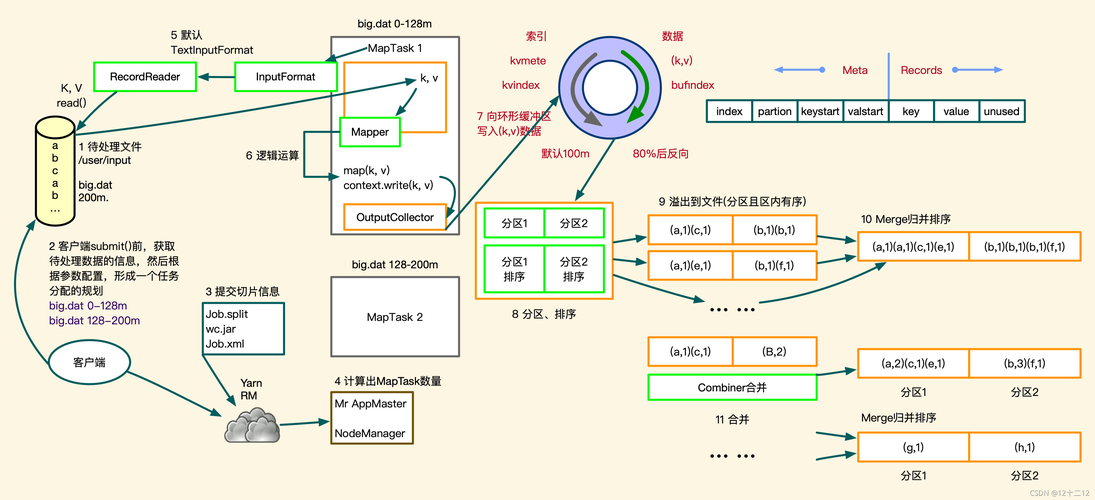
数据拉取过程
HTTP方式文件获取
不同来源数据合并
5、MapReduce编程模型
核心思想与数据处理
Mapper与Reducer角色
转换操作与输出格式
6、MapReduce关键组件
Mapper功能与实现
Reducer设计要点
数据流与容错性
7、数据传输优化策略
性能提升技巧
数据本地化优势
网络传输成本降低
8、数据安全与可靠性
可靠容错式并行处理
大规模集群上运行保障
TB级数据处理稳定性
9、高级特性与扩展性
自定义Partitioner应用
扩展接口与API使用
支持非结构化数据处理
MapReduce数据传输机制是处理大规模数据集时不可或缺的一环,通过上述的详细解析,可以发现MapReduce不仅在数据处理方面提供了高效的解决方案,同时也为数据传输提供了稳定可靠的支持,从Map阶段的数据分块到Reduce阶段的聚合操作,再到Copy和Merge阶段的数据拉取与合并,每一个环节都经过精心设计,以确保数据在分布式环境中能够高效、安全地传输,通过优化策略和高级特性的应用,MapReduce能够进一步提升数据传输的效率和扩展性,满足不同场景下的数据处理需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/828007.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复