


MapReduce操作HBase数据,是处理大规模数据集的一种高效方法,下面将详细解析如何通过MapReduce读取和写入HBase数据,以及如何进行数据统计和分析,具体如下:


1、环境准备
启动HDFS和HBase:在开始任何操作前,需要启动HDFS和HBase服务,可以通过运行startdfs.sh 和starthbase.sh 脚本来分别启动它们。
进入HBase Shell:启动HBase后,为了执行基本的HBase操作,如创建表、插入数据等,需要进入HBase Shell命令行界面,通过运行hbase shell 命令进入。
2、数据准备
创建HBase表:在HBase Shell中,可以使用create 命令创建需要的表,如创建名为 ‘word’ 的表,并设置列族为 ‘content’。
插入数据:使用put 命令可以向表中插入数据,例如向 ‘word’ 表插入两段文本数据,以备后续处理。
3、读取HBase数据
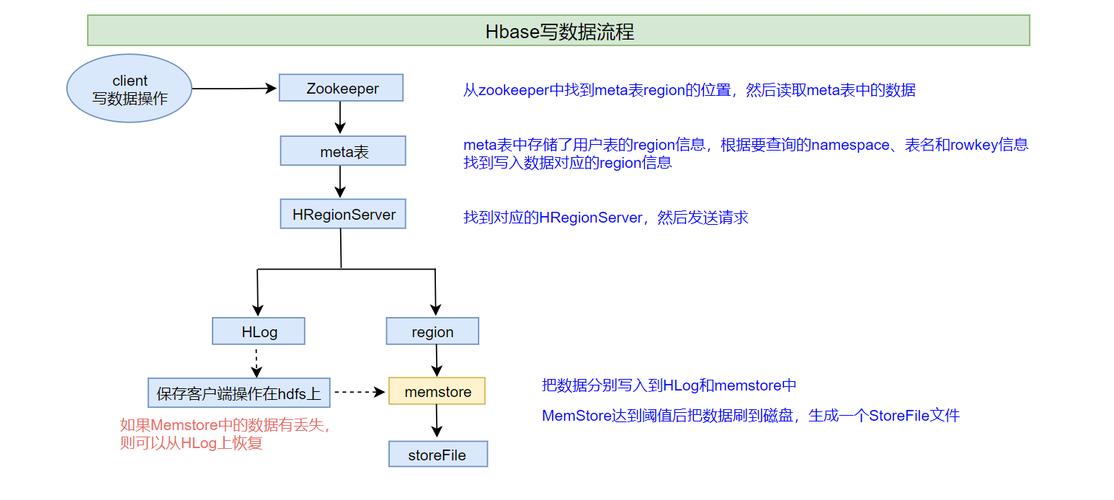
使用MapReduce读取:通过编写MapReduce作业,可以读取存储在HBase中的数据,在Map阶段,可以对读取到的数据进行处理,如进行词频统计。
配置输入输出格式:在MapReduce作业配置中,需要使用TableInputFormat 和TableOutputFormat 来分别指定HBase表作为数据的源和目标。
4、数据处理与输出
词频统计案例:以词频统计为例,MapReduce作业可以在Map阶段读取HBase中的文本数据,并对单词进行计数,在Reduce阶段汇归纳果,并把结果写回HBase中。
数据拷贝案例:另一个常见的用途是将HBase表中的数据拷贝到另一张表中,这可以通过MapReduce来实现,并且在Map阶段完成数据的读取和转换。
5、数据导入HBase
从本地文件系统导入:除了从HBase读取数据,MapReduce还可以将本地文件系统或者HDFS中的数据导入到HBase中,这通常用于数据的批量加载。
自定义Mapper类:在实现数据导入时,需要自定义Mapper类来处理输入数据,并将其转换为HBase可以接受的格式,然后通过HBase的API进行数据插入。
操作中涉及的关键技术包括HBase的JavaAPI、Hadoop的MapReduce框架、TableInputFormat和TableOutputFormat类等,这些技术确保了在处理大规模数据集时的性能和效率,在实践过程中,还需要注意不同版本间可能存在的兼容性问题,以及合理设计Map和Reduce函数来优化性能。
使用MapReduce操作HBase数据涉及环境的准备工作、数据的初始化、读取HBase数据、数据的处理与输出,以及利用MapReduce进行数据分析,这些操作展示了HBase与MapReduce结合的强大能力,对于处理大规模数据集来说,这些技能是至关重要的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/827059.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复