


在当今数据驱动的时代,大数据挖掘与机器学习已经成为企业决策和创新的核心驱动力,本文将详细解析机器学习端到端的场景,帮助企业和个人理解如何通过大数据处理平台如MaxCompute,实现从数据收集到模型部署的全流程管理。

大数据挖掘是利用复杂的算法从大量数据中提取信息的过程,这一过程通常包括数据采集、预处理、分析建模和结果解释等关键步骤,在大数据环境下,机器学习的角色尤为关键,它能够通过算法自动发现数据中的模式,并用于预测未来的数据趋势或行为。
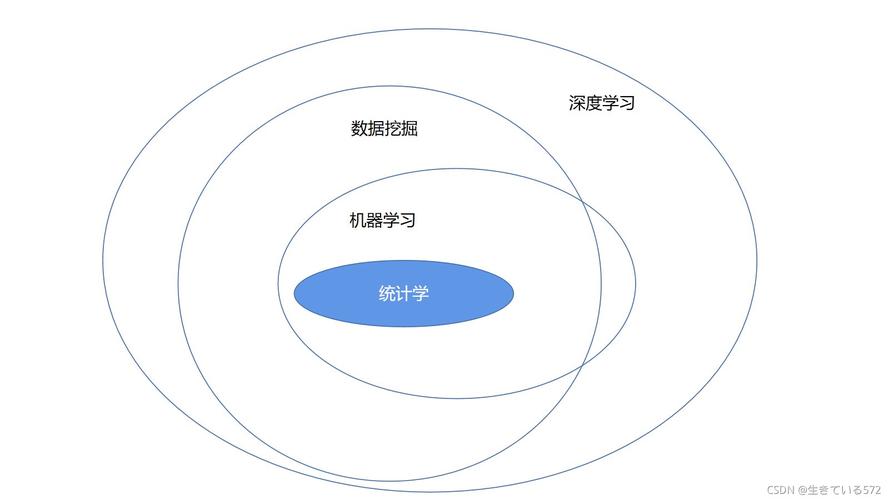
了解机器学习的基本流程对实现端到端的机器学习场景至关重要,机器学习项目的实施可以分为几个阶段:定义问题、收集数据、数据处理、选择模型、训练模型、评估模型、参数调整和优化、部署模型和模型监控,每个阶段都需要精心规划和执行,确保最终模型的准确性和可靠性。
在实际操作中,选择合适的大数据处理和机器学习平台至关重要,MaxCompute提供了一个全面的数据处理平台,支持从数据存储到分析的多种需求,包括但不限于数据挖掘和机器学习,这类平台的强大功能可以帮助用户高效地处理海量数据,同时保证数据的安全和访问的可控性。
机器学习模型的开发过程中,数据的质量直接影响到模型的效果,高质量的数据需要通过数据清洗、特征工程等方法进行预处理,以减少噪声和偏差,提高模型的精确度和泛化能力,选择合适的特征和算法对于解决特定问题也非常关键。
在模型训练阶段,开发者需要根据具体问题选择相应的学习算法,如回归分析、决策树、神经网络等,这些算法各有优缺点,适用于不同类型的数据和问题,训练后的模型需要进行严格的测试和评估,以确保其在实际环境中可以正常工作,这通常涉及到使用交叉验证、A/B测试等技术来避免过度拟合,并评估模型的泛化能力。
机器学习模型的部署和监控是端到端流程的最后阶段,部署的模型需要持续监控其性能,根据反馈调整参数,优化模型表现,随着数据环境的变化,可能需要周期性地重新训练模型以维持其准确性和相关性。
归纳而言,端到端的机器学习实施是一个复杂但条理清晰的过程,从数据采集到模型部署,每一步都需精心设计与执行,确保最终的机器学习模型能够在实际应用中发挥最大的效果,而优秀的大数据处理平台如MaxCompute为这一过程提供了强大的技术支持和资源保障。
相关问答 FAQs
Q1: 如何选择适合的机器学习算法?
A1: 选择机器学习算法时,应考虑数据的大小、质量和特征,以及问题的类型(分类、回归或聚类),了解每种算法的优势和局限性,结合实际情况,有时甚至需要尝试多种算法来确定最佳选择。
Q2: 如何评估机器学习模型的性能?
A2: 可以通过多种指标来评估模型性能,如准确率、召回率、F1分数等,使用交叉验证可以检验模型的泛化能力,对于时间序列数据,还可以使用滚动预测精度等指标来评估模型的稳定性和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/827050.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复