


ORC Format


ORC (Optimized Row Columnar) is a columnar storage file format designed for Hadoop workloads. It provides efficient data compression and encoding schemes, as well as support for complex types like nested structures and dates. ORC files are optimized for both read and write operations, making them ideal for largescale data processing tasks.
Key Features of ORC Format
| Feature | Description |
| Columnar Storage | Stores data in a columnwise fashion, which allows for efficient data access and filtering. |
| Compression | Uses various compression techniques to reduce the size of the stored data. |
| Efficient Data Access | Supports fast data access by skipping unnecessary columns during query execution. |
| Schema Evolution | Allows schema changes without requiring rewrites of the entire dataset. |
| Complex Data Types | Supports complex data types like structs, arrays, maps, and dates. |
| Partitioning | Supports partitioning of data based on userdefined criteria. |
| ACID Transactions | Ensures data consistency and integrity during concurrent writes. |
ORC File Structure
An ORC file consists of several components:
1、File Header: Contains metadata about the file, such as the number of rows, columns, and their types.
2、Row Index: Provides a mapping from row numbers to the start position of each row in the stripes.
3、Stripes: Contain the actual data in a columnar format. Each stripe contains one or more rows of data.
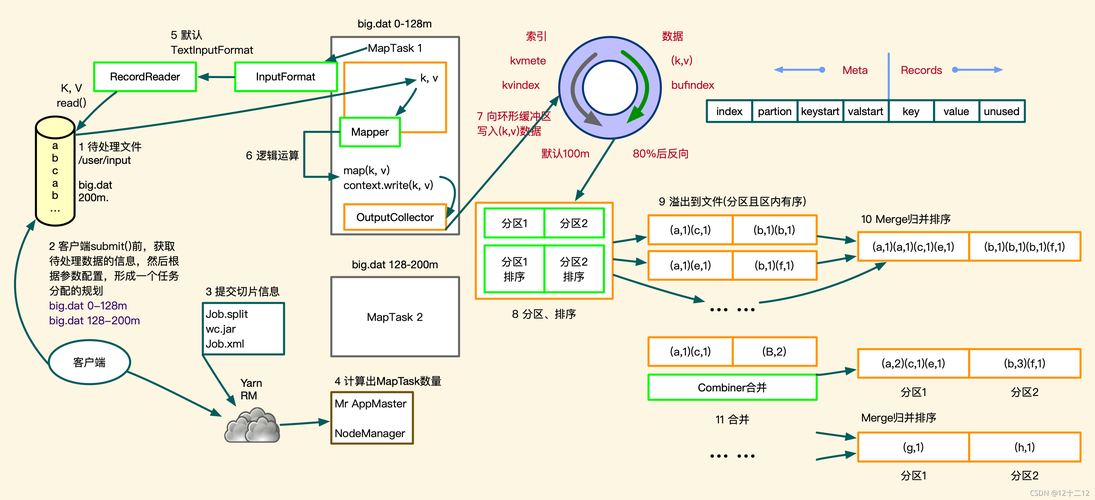
4、Footer: Contains additional metadata, such as statistics about the data.
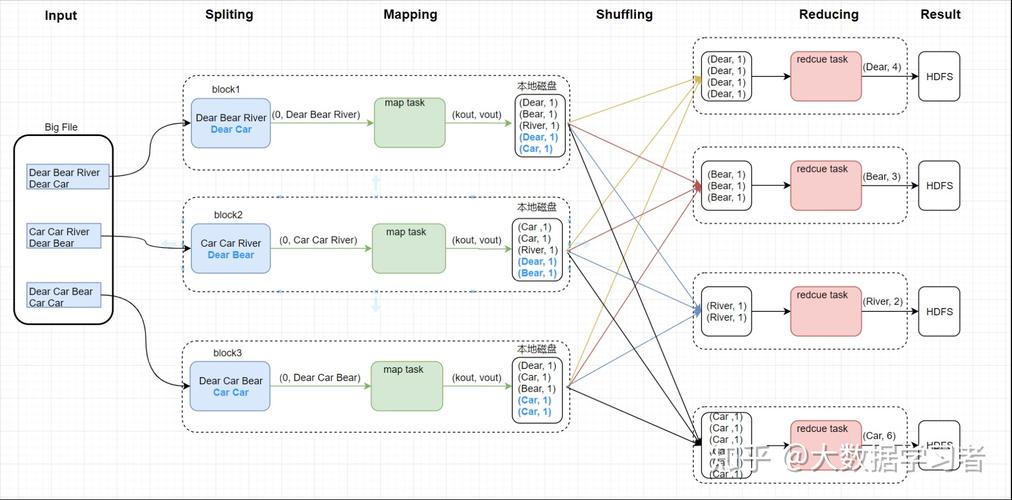
Using ORC with MapReduce
ORC files can be processed using MapReduce jobs just like any other file format. TheOrcInputFormat andOrcOutputFormat classes provide input and output support for ORC files.
Reading ORC Files with MapReduce
To read an ORC file in a MapReduce job, you need to set up theOrcInputFormat class in your job configuration:
Job job = Job.getInstance(new Configuration());
FileInputFormat.addInputPath(job, new Path("path/to/orc/file"));
OrcInputFormat.setInputPathFilter(job, OrcInputFormat.class); Writing ORC Files with MapReduce
To write data to an ORC file using MapReduce, you need to use theOrcOutputFormat class:
Job job = Job.getInstance(new Configuration());
FileOutputFormat.setOutputPath(job, new Path("path/to/output/directory"));
OrcOutputFormat.setOutputPath(job, new Path("path/to/output/orc/file")); By leveraging the ORC format and its integration with MapReduce, you can efficiently process large datasets while taking advantage of the benefits provided by the columnar storage format.
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/826784.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复