


MapReduce框架是面向大规模数据集(大于1TB)的并行运算编程模型,包括Map阶段和Reduce阶段,下面将详细介绍MapReduce框架下的应用开发中常用概念,并使用小标题和单元表格进行清晰展示:
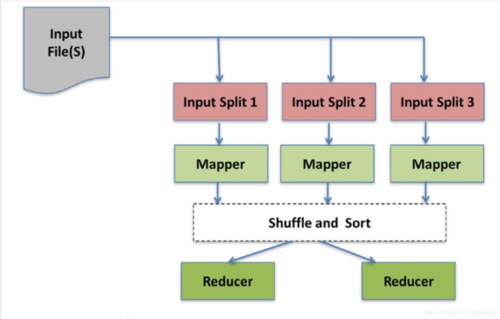

MapReduce 基础概念
定义
MapReduce:是一种编程模型,用于处理和生成大规模数据集,包含Map阶段和Reduce阶段,分别用于数据处理和数据聚合。
核心组件
Mapper:负责将输入数据转换为键值对,并输出中间结果。
Reducer:负责接收具有相同键的值,并将其合并为较少的值。
数据流
InputFormat:解析输入数据格式,并将数据分片以便Map任务进行处理。
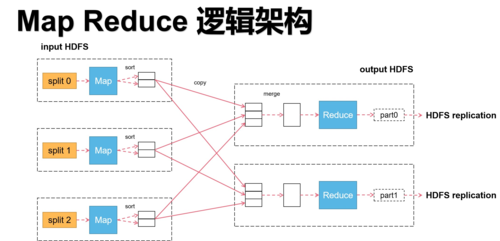
Output:最终的结果以key/value对的形式写入到HDFS(Hadoop分布式文件系统)中。
编程模型
Map函数
接受原始数据,产生一系列中间键值对。
中间数据存储在本地磁盘上,默认按键(Key)聚集。
Reduce函数
接受Map阶段的输出,将具有相同键的值列表合并,产生最终结果。
作业执行流程
作业提交
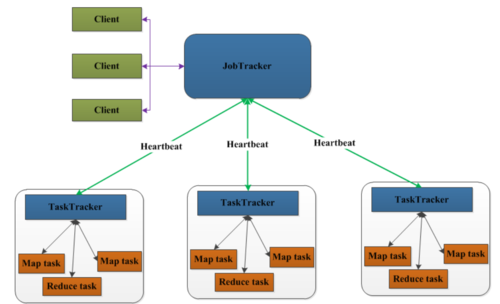
用户提交MapReduce作业至Hadoop集群。
作业初始化
MapReduce框架根据配置分割作业并分配任务。
任务分配与执行
Hadoop集群中的节点分别执行Map或Reduce任务。
结果写回
执行完毕后,结果写回HDFS。
MapReduce优缺点
优点
易于编程与扩展。
高容错性和数据本地化优势。
适用于处理PB级别大数据集。
缺点
实时处理性能不足。
对流式数据处理支持较弱。
应用开发考虑因素
数据倾斜问题
当某些Key的数据量特别大时,可能导致个别Reduce任务执行缓慢,影响整体作业执行时间。
资源分配
根据实际数据大小和集群能力合理配置Map和Reduce任务数量。
容错性设计
MapReduce框架具有一定的容错机制,开发者应充分利用这一点来保证作业稳定运行。
是MapReduce框架下的应用开发中一些核心概念的详细解析,掌握这些基本概念有利于更好地理解和使用MapReduce进行大数据处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/826577.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复