


导出MySQL数据库并导入Hive数据库
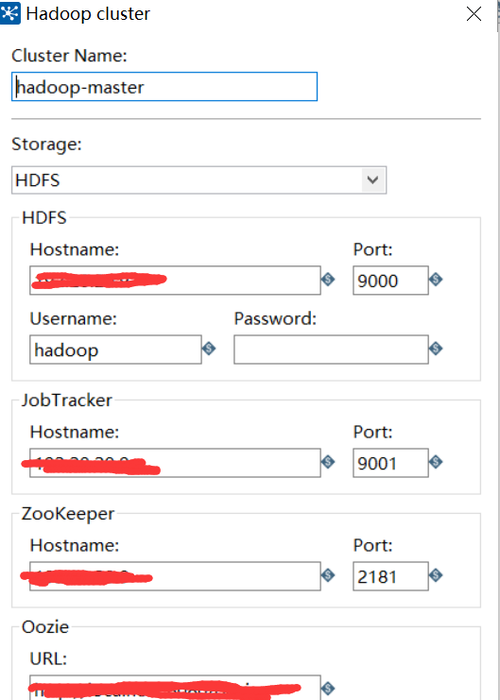

导出MySQL数据库
使用mysqldump命令
1、基本用法:mysqldump是MySQL数据库中最常用的备份工具之一,它允许用户导出数据库的结构和数据,要导出名为exampleDB的数据库,可以使用以下命令:
mysqldump u username p exampleDB > exampleDB.sql
2、导出特定表:如果只需要导出数据库中的某个表,可以加入tables参数,如:
mysqldump u username p databases exampleDB tables exampleTable > exampleDB_exampleTable.sql
3、导出数据结构:有时,只需导出数据库的结构而不包括数据,这可以通过添加nodata参数实现:
mysqldump u username p nodata exampleDB > exampleDB_structure.sql
4、数据压缩:为了节省存储空间和提高传输效率,可以将导出的数据进行压缩:
mysqldump u username p exampleDB | gzip > exampleDB.sql.gz
使用SELECT…INTO OUTFILE语句
除了mysqldump外,MySQL还支持通过SQL查询直接将查询结果导出到文件,这通常用于导出表中的部分数据:
SELECT * FROM exampleTable INTO OUTFILE '/path/to/outputfile.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY ' ';
导入到Hive数据库
从本地文件系统导入
1、创建Hive表:在导入数据之前,需要首先在Hive中创建一个对应表结构,为上述CSV文件创建一个表:
CREATE TABLE hiveTable (column1 string, column2 int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY ' ' STORED AS TEXTFILE;
2、导入数据:使用LOAD DATA LOCAL INPATH命令将本地文件导入到Hive表中:
LOAD DATA LOCAL INPATH '/path/to/outputfile.csv' INTO TABLE hiveTable;
从HDFS导入
如果数据已经存在于HDFS上,直接使用LOAD DATA INPATH导入:
LOAD DATA INPATH 'hdfs://path/to/outputfile.csv' INTO TABLE hiveTable;
使用Sqoop导入
Sqoop是一个在Hadoop和关系型数据库之间高效传输大批量数据的工具,使用Sqoop从MySQL导入数据到Hive:
sqoop import connect jdbc:mysql://hostname/database username username password password table mysqlTable hiveimport createhivetable hivetable hiveTable
相关FAQs
Q1: 如何在不停机的情况下备份MySQL数据库?
A1: 可以使用singletransaction选项与mysqldump命令一起使用,这确保了在导出过程中,MySQL使用一个事务来确保数据的一致性,适用于大多数事务表:
mysqldump singletransaction u username p database > backup.sql
Q2: Hive支持哪些数据格式?如何选择合适的格式?
A2: Hive支持多种数据格式,包括但不限于TEXTFILE, SEQUENCEFILE, ORC, PARQUET等,选择格式时考虑查询性能和存储效率,ORC和PARQUET提供了高效的压缩和快速的查询性能,适合大型数据集,而TEXTFILE简单易用,适合简单的文本数据:
CREATE TABLE orcTable (columns...) STORED AS ORC; CREATE TABLE parquetTable (columns...) STORED AS PARQUET;
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/826210.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复