


断点续传下载

在现代网络传输中,断点续传技术是一种非常重要的功能,特别是在文件下载、大数据传输等场景下,它允许用户在传输中断后,从断点处继续传输,而不是重新开始,这项技术大大提高了传输效率,节省了时间和资源,本文将通过一个断点续传下载的实例来详细介绍其工作原理和实现方法。
断点续传的基本原理
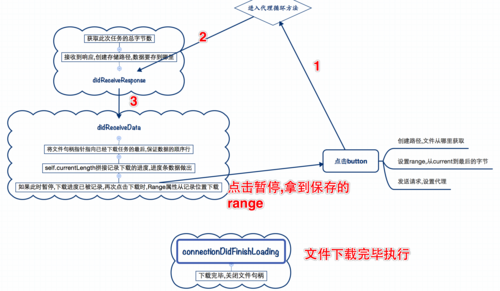
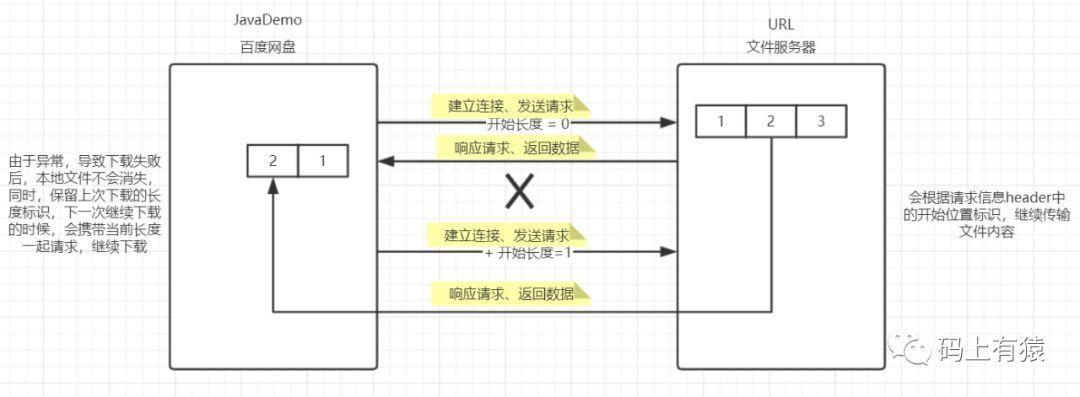
断点续传的核心在于能够记录上次传输停止的位置,并在下次开始传输时从此位置继续进行,这通常通过HTTP/FTP协议中的Range头部来实现,服务器需要支持Range请求,以便客户端可以请求特定范围的数据。
实例详解
假设有一个10MB大小的文件需要下载,我们将通过以下步骤展示如何实现断点续传下载。
准备阶段
1、服务器配置: 确保服务器支持HTTP Range头部,允许客户端请求文件的特定部分。
2、客户端实现: 客户端软件需要能够发送带有Range头部的HTTP请求,并处理接收到的数据。
下载过程
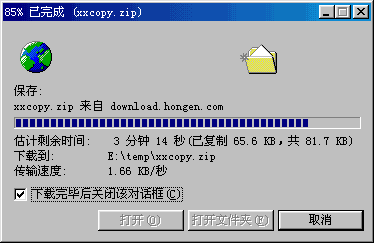
1、首次下载: 客户端向服务器请求整个文件,如果下载过程中断,客户端记录已下载的字节数(已下载2MB)。
2、中断发生: 由于网络问题或其他原因,下载在2MB处中断。
3、续传请求: 客户端再次启动时,检测到有2MB的数据已经下载,于是发送一个新的请求,请求从第2MB之后的数据(即字节范围2097152,表示从第2097153字节到文件末尾)。
4、服务器响应: 服务器收到Range请求后,只发送请求范围内的数据,客户端接收这部分数据并将其追加到已下载的部分。
5、完成下载: 客户端持续此过程,直到整个文件下载完成。
关键代码示例
假设使用Python实现一个简单的断点续传下载器:
import requests
def download_file(url, filename, start_byte=0):
headers = {'Range': f'bytes={start_byte}'}
response = requests.get(url, headers=headers, stream=True)
with open(filename, 'ab') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
return response.status_code
首次下载尝试
download_file('http://example.com/largefile.zip', 'largefile.zip')
假设下载中断,已下载2MB
previously_downloaded = 2 * 1024 * 1024 # 2MB in bytes
从断点处继续下载
download_file('http://example.com/largefile.zip', 'largefile.zip', previously_downloaded) 优化与进阶
错误处理: 增加异常捕获逻辑,以应对网络不稳定等情况。
多线程下载: 利用多线程或多进程同时请求文件的不同部分,以提高下载速度。
进度显示: 提供用户界面显示当前下载进度和速率,增强用户体验。
相关问答FAQs
Q1: 如果服务器不支持Range请求,我还能实现断点续传吗?
A1: 如果服务器不支持Range请求,传统的断点续传方式将不可行,不过,你可以考虑一些替代方案,如使用第三方下载管理器,它们可能提供了其他机制来支持断点续传,可以考虑与服务器管理员联系,请求他们启用Range支持。
Q2: 断点续传是否适用于所有类型的数据传输?
A2: 断点续传主要适用于基于HTTP/HTTPS的文件下载,对于实时数据流、数据库同步、或其他特定类型的数据传输,可能需要采用不同的策略和技术来实现类似的功能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/826061.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复