


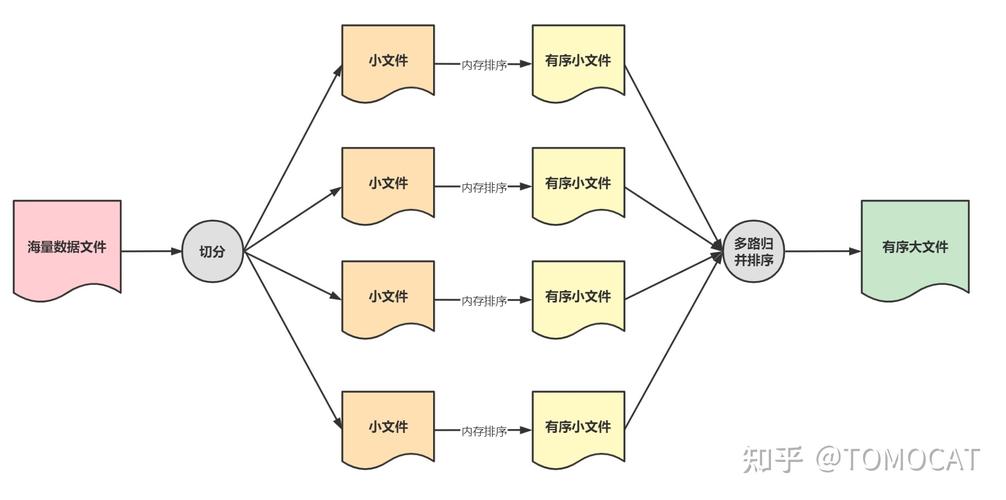
MapReduce外部排序是一种处理大数据的技术,通过将数据分成多个部分并行处理来提高效率。每个部分独立排序后合并结果,适合处理超出内存容量的大数据集。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,外部排序是MapReduce的一个常见应用,它涉及将大量数据分成多个部分,对每个部分进行排序,然后将这些排序的部分合并成一个完全排序的结果集。

(图片来源网络,侵删)
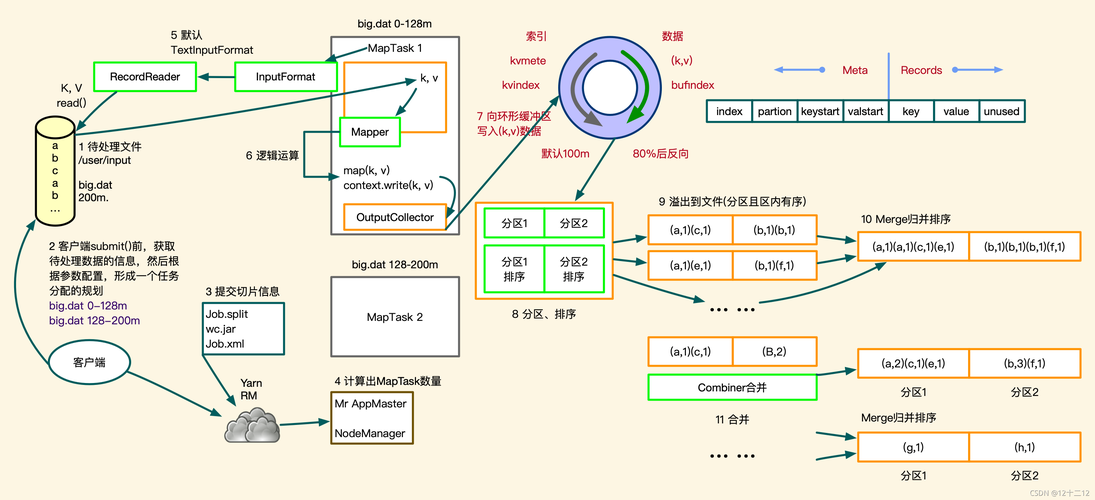
下面是一个简化的MapReduce外部排序过程的步骤:
1、分割阶段(Map):
输入数据被分割成多个小文件或块。
每个块独立地进行内部排序。
输出为已排序的文件块。
2、归并阶段(Reduce):
读取所有已排序的文件块。
(图片来源网络,侵删)
使用一个优先队列或其他数据结构来合并这些块,以产生一个完全排序的结果集。
下面是一个简单的伪代码示例,展示了MapReduce外部排序的基本概念:
Map阶段
def map(input_data):
# 对输入数据进行分割,这里假设input_data是一个包含大量数据的列表
chunks = split_into_chunks(input_data)
# 对每个块进行排序
sorted_chunks = [sorted(chunk) for chunk in chunks]
return sorted_chunks
Reduce阶段
def reduce(sorted_chunks):
# 创建一个优先队列来存储最小的元素
min_heap = MinHeap()
# 将所有排序后的块的第一个元素添加到优先队列中
for chunk in sorted_chunks:
if chunk:
min_heap.insert(chunk[0])
# 结果列表
result = []
# 当优先队列不为空时,从中取出最小元素并将其添加到结果列表中
while min_heap:
min_value = min_heap.extract_min()
result.append(min_value)
# 从对应的块中获取下一个元素并插入到优先队列中
for i, chunk in enumerate(sorted_chunks):
if chunk and chunk[0] == min_value:
if len(chunk) > 1:
min_heap.insert(chunk[1])
sorted_chunks[i] = chunk[1:]
break
return result
主函数
def external_sort(input_data):
sorted_chunks = map(input_data)
sorted_result = reduce(sorted_chunks)
return sorted_result 上述伪代码是为了说明MapReduce外部排序的概念而编写的,并不是实际可执行的代码,在实际的MapReduce框架中,如Hadoop或Spark,这个过程会被自动地并行化和优化。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/825584.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复