


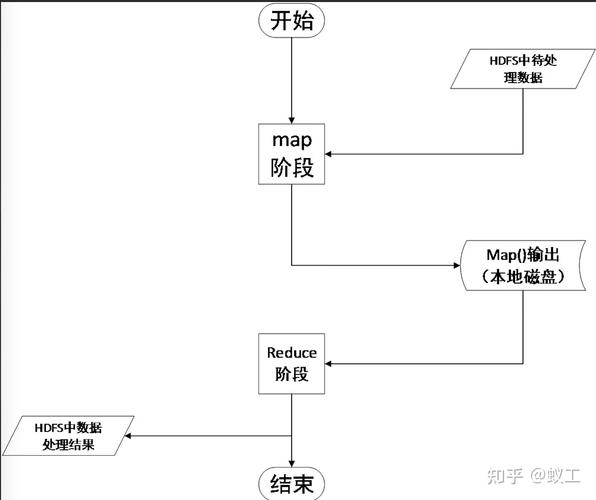
MapReduce 执行流程主要包括以下几个步骤:

1、数据分割(InputSplit)
2、映射阶段(Mapper)
3、排序和分区(Sort and Shuffle)
4、归约阶段(Reducer)
5、输出结果(Output)
下面是详细的执行流程:
1、数据分割(InputSplit)
在 MapReduce 任务开始之前,首先需要将输入数据分割成若干个数据块(InputSplit),每个数据块对应一个 Mapper 任务,通常情况下,数据块的大小与 HDFS 的块大小相同,默认为 64MB。
2、映射阶段(Mapper)
Mapper 任务负责处理输入数据块,并将处理结果输出为键值对(keyvalue),Mapper 的输出结果会被写入到本地磁盘上的临时文件中。
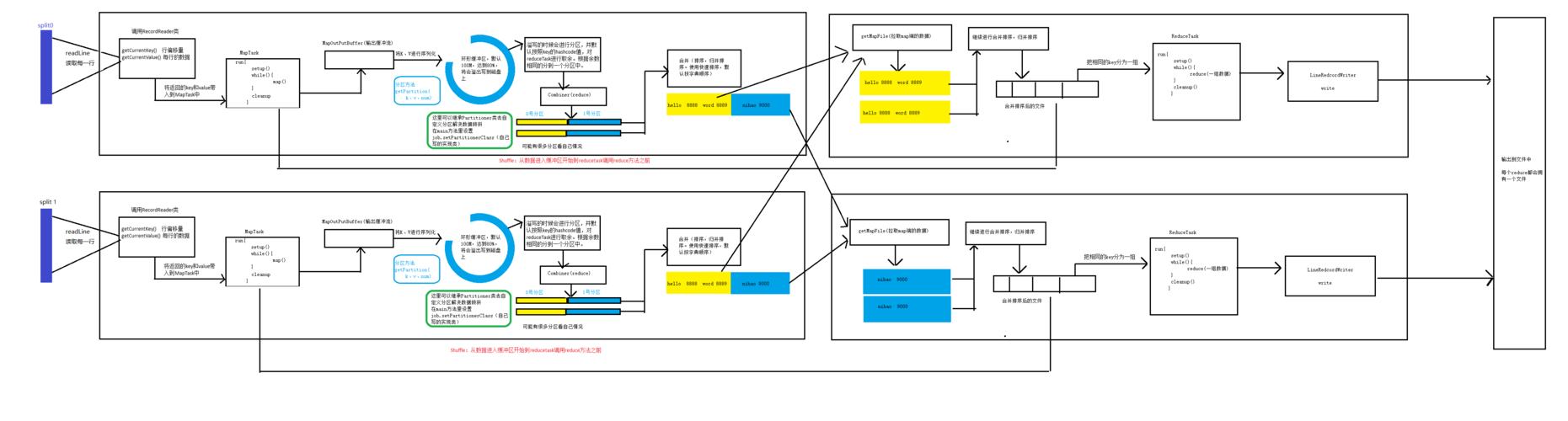
3、排序和分区(Sort and Shuffle)
在 MapReduce 执行过程中,Shuffle 阶段负责将 Mapper 输出的键值对进行排序、分区和合并,具体过程如下:
排序(Sort):对 Mapper 输出的键值对按键进行排序。
分区(Partition):根据键的值将排序后的键值对分配到不同的 Reducer 任务。
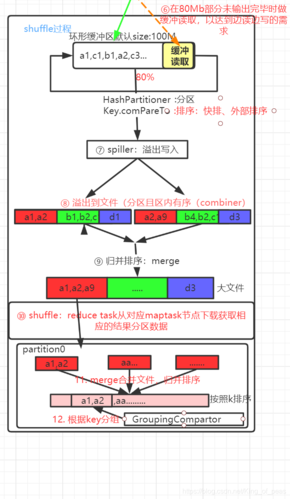
合并(Combine):可选操作,用于在 Mapper 端对输出结果进行局部汇总,减少网络传输的数据量。
4、归约阶段(Reducer)
Reducer 任务负责处理从 Mapper 任务接收到的数据,并将最终结果输出到 HDFS,具体过程如下:
读取数据:Reducer 任务从各个 Mapper 任务中获取属于自己的数据。
归约操作:对读取到的数据进行归约操作,例如求和、计数等。
输出结果:将归约后的结果输出到 HDFS。
5、输出结果(Output)
Reducer 任务将最终结果输出到 HDFS,完成整个 MapReduce 任务。
下面是一个简单的单元表格,展示了 MapReduce 执行流程的关键步骤:
| 步骤 | 描述 |
| 数据分割 | 将输入数据分割成若干个数据块 |
| 映射阶段 | 处理数据块并输出键值对 |
| 排序和分区 | 对键值对进行排序、分区和合并 |
| 归约阶段 | 处理从 Mapper 任务接收到的数据并输出结果 |
| 输出结果 | 将最终结果输出到 HDFS |
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/825450.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复