


在现代的数据库架构中,读写分离是一种常见的策略,旨在提高数据库的性能和可用性,通过将读操作和写操作分配到不同的服务器上,可以有效地平衡负载,减少单个节点的压力,并提高系统整体的处理能力,而副本集高可用则是确保数据持久性和访问连续性的关键机制,它通过维护多个数据副本来实现。
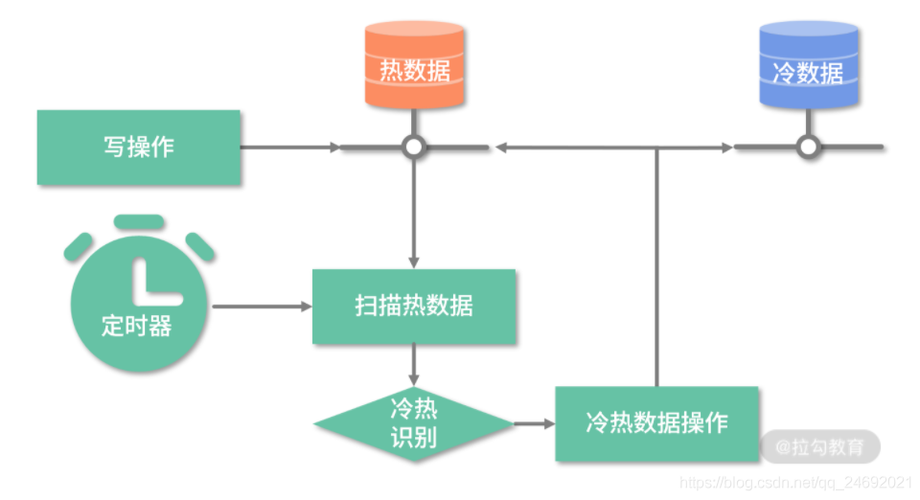

实现读写分离的步骤:
1. 设置主从复制
要实现读写分离,首先需要配置主从复制,使得一个数据库服务器(主库)上的数据更新能够同步到其他服务器(从库),这通常涉及到以下步骤:
选择一台服务器作为主库,处理所有的写请求。
其他服务器设置为从库,仅用于读取数据。
配置从库以订阅主库的二进制日志,实时同步数据更改。
2. 修改客户端连接
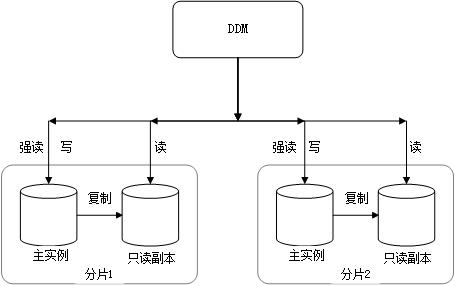
应用程序或中间件需要进行相应的配置,以确保它们能够区分读请求和写请求,并将它们分别发送到正确的服务器,这可能包括:
在应用程序代码中直接指定读写分离逻辑。
使用负载均衡器或代理服务器来路由请求。
3. 监控和维护
实施读写分离后,需要对系统进行持续监控,以确保:
主从复制正常运作,没有延迟或错误。
读写分离逻辑正确无误地执行。
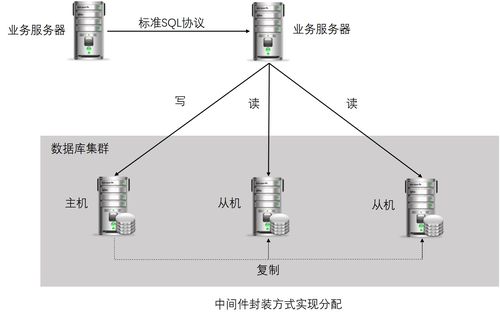
及时处理任何故障转移情况。
实现副本集高可用的策略:
1. 多副本部署
为了实现高可用,至少需要部署两个以上的数据副本,这些副本可以是热备或冷备,根据业务需求和资源情况来决定。
2. 自动故障转移
配置故障转移机制,以便在一个节点失效时,其他节点能够接管服务,在MongoDB等数据库中,这通常是通过选举机制来实现的。
3. 监控和报警
建立监控系统来跟踪每个节点的状态,一旦检测到异常,立即触发报警并采取相应措施。
4. 定期备份和恢复测试
即使有多个实时副本,也需要定期进行数据备份,并进行恢复测试,以确保在任何情况下都能恢复数据。
相关问答FAQs
Q1: 读写分离是否适合所有类型的数据库应用?
A1: 读写分离特别适合读多写少的应用,比如内容管理系统、博客平台等,但对于写密集型应用,如高速交易处理系统,读写分离可能不会带来太大的性能提升,因为写操作仍然集中在主库上,对于需要强一致性的场景,读写分离也可能不是最佳选择,因为它可能导致读取到的数据稍有滞后。
Q2: 在实施读写分离时,如何保证数据的一致性?
A2: 保证数据一致性的关键在于主从复制的配置和监控,需要确保从库能够及时同步主库上的数据更改,并且当复制滞后或失败时,要有机制通知管理员进行处理,在某些情况下,可能需要牺牲一定的性能来保证更强的一致性级别,例如使用同步复制代替异步复制。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/823940.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复