


在当前时代,大数据处理已成为许多行业不可或缺的一部分,而MapReduce作为处理大规模数据集的编程模型,在此领域发挥着重要作用,Windows系统下的开发者也常常需要远程提交MapReduce任务到Hadoop集群,下面将详细探讨如何通过Windows系统提交MapReduce任务:

1、配置环境
客户端配置:为了在Windows上运行MapReduce任务,需要先安装并配置Hadoop客户端,可以从集群中复制hadoop文件夹到Windows机器上,然后进行必要的设置。
配置文件修改:Hadoop的运行依赖于配置文件,如mapredsite.xml和yarnsite.xml,这些文件告诉Hadoop如何运行作业和利用资源,在远程提交时,需确保客户端能正确读取这些配置。
跨平台参数配置:为了让Linux服务器接受来自Windows系统的提交,需要在mapredsite.xml配置文件中设置“mapreduce.appsubmission.crossplatform”参数为“true”,以启用跨平台提交功能。
2、连接集群
使用SSH连接:Windows系统可以通过SSH(Secure Shell)协议远程连接到Hadoop集群,这通常需要SSH客户端工具,如PuTTY,来建立连接。
配置hosts文件:如果在Hadoop的配置文件中使用了域名,而不是IP地址,则需要在Windows系统的hosts文件中添加相应的域名解析,以确保可以正确地解析集群地址。
3、身份和权限
用户匹配:在远程操作时,需保证Windows系统使用的用户名在Hadoop集群上也具有相应的账户和权限,必要时可以将Windows的用户名改成与集群上相同的用户名,例如将administrator改为hadoop。
4、IDE集成
远程调试:通过配置集成开发环境(IDE),如IntelliJ IDEA,可以本地模拟远程Hadoop集群的行为,直接运行和调试MapReduce任务,提高开发效率。
5、Windows特定设置
winutils配置:Windows下运行Hadoop需要特定的winutils工具,需要将这些工具解压并复制到hadoop的bin和lib目录下。
环境变量设置:在Windows系统中,还需要设置HADOOP_HOME环境变量,并把相关路径添加到PATH变量中,使命令可以在命令提示符下全局执行。
6、代码和资源管理
上传资源文件:在提交MapReduce作业之前,可能需要上传相关的资源文件(如jar包、输入数据等)到HDFS或其它存储系统中。
依赖管理:管理作业依赖是至关重要的,要确保所有必需的库和依赖在远程集群上也是可用的。
7、作业提交与监控
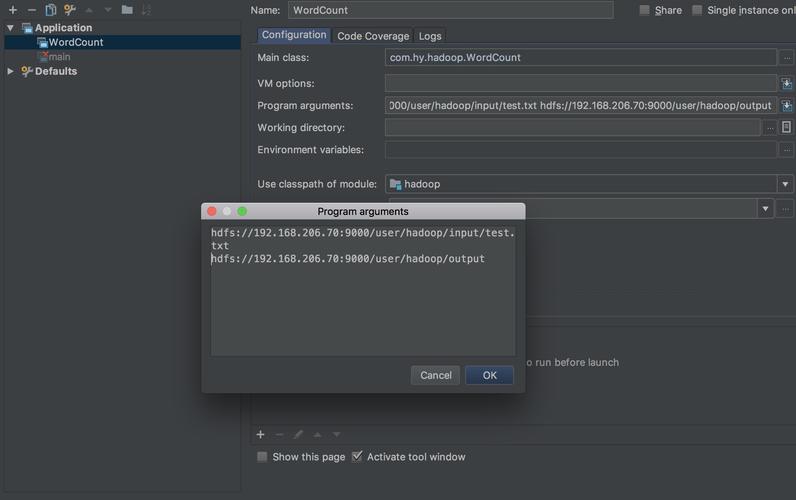
提交作业:使用hadoop jar命令或者通过编写Java程序的方式,可以远程提交MapReduce作业到集群。
进度监控:作业提交后,可以使用Web界面或者命令行工具来监视作业的运行状态和进度。
结果获取:作业完成后,可以从HDFS或者通过其他方式获取作业输出结果。
8、故障排查
日志检查:出现问题时,要查看Hadoop集群和客户端的日志文件,识别和解决潜在的问题。
网络检查:确认Windows客户端与Hadoop集群之间的网络连接是正常的,包括网络延迟和数据可达性。
在上述过程中,还应注意以下要点:
在进行远程提交前,应测试SSH连接是否正常,以及是否能够正确访问Hadoop集群地址。
配置文件的修改应当谨慎,避免因格式错误或参数设置不当导致作业无法正常提交或运行。
对于数据的输入输出,应当事先规划好文件的存放位置及访问权限,确保作业可以顺利读写数据。
在Windows系统下远程提交MapReduce任务到运行在Linux上的Hadoop集群,需要对环境进行适当配置,并采取特定步骤确保作业的正常提交和执行,遵循上述步骤,可以有效地实现跨平台地大数据处理任务,同时保障作业的稳定性和高效性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/823916.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复