


大数据在当今社会的许多领域都发挥着至关重要的作用,尤其是在人工智能和机器学习领域,大模型微调是这些领域中的一项关键技术,它允许模型针对特定任务进行优化,从而提高性能和精确度,为了实现有效的微调,数据集的选择和使用是非常关键的,选择合适的数据不仅影响模型的性能,还决定了模型是否能够在特定领域内达到预期的效果,大模型微调过程中对数据的要求是严格的,并需要精心策划和执行。
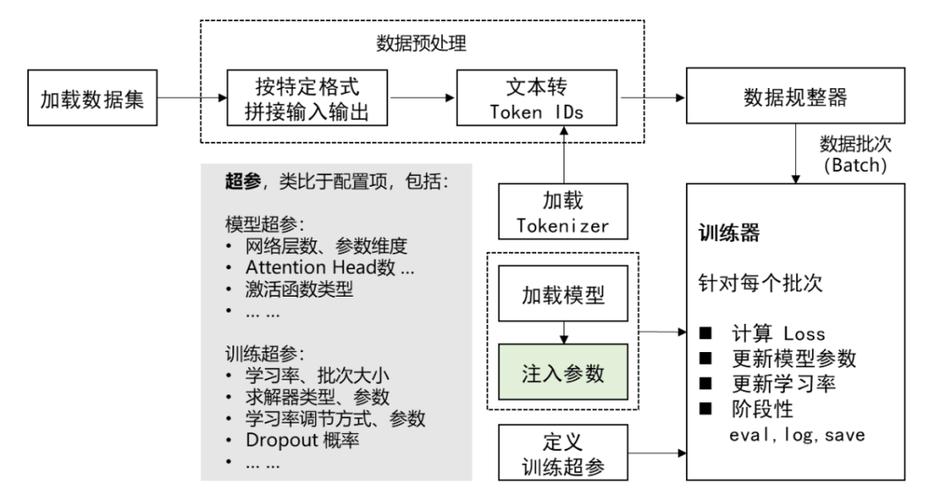

理解大模型微调的基本步骤和目的是重要的,大模型微调通常涉及选择相关的数据集和预训练模型,然后通过设置合适的超参数对模型进行调整,最后使用特定任务的数据对模型进行训练以优化其性能,这一过程的成功在很大程度上依赖于所选数据的质量、相关性以及数据的规模。
数据质量是一个关键考虑因素,高质量的数据应该具备准确性、一致性和清洁性,没有错误的标签、不相关的信息或噪声,在进行情感分析的微调时,如果训练数据包含了错误标记的正面或负面例子,那么模型可能会学习到错误的模式,从而影响其判断准确性。
数据的相关性也极为重要,对于特定领域的任务,如医学影像处理或法律文件分析,必须使用该领域内的数据集进行微调,这样可以确保模型能够学习到领域内特定的知识和信息,从而提高其在该领域的性能表现,使用医学影像数据集微调的模型,将更擅长识别和分析医学影像,而使用法律文本数据集微调的模型,则能更好地理解和分析法律文件。
数据规模的影响同样不容忽视,一般而言,数据量越大,模型训练的结果越稳定,过拟合的风险也越小,数据规模的增加也意味着更大的存储和处理需求,这可能增加计算成本和时间,适当的数据规模取决于具体的应用需求和可用资源。
除了上述基本的数据要求之外,成功的大模型微调还需要注意以下几个方面:
1、数据多样性:确保训练数据覆盖各种场景和条件,可以提高模型的泛化能力。
2、持续更新:随着时间推移,领域内的信息可能会发生变化,定期更新训练数据可以确保模型保持最新状态。
3、伦理和隐私:在处理敏感数据时,必须遵守相关的伦理和隐私标准,确保数据的安全和合规使用。
大模型微调是一个复杂但极具价值的过程,它能够让模型在特定任务上达到更高的性能,通过确保使用高质量、相关且适量的数据集,可以大大提高微调效果,使模型更加精确和有效,合理的数据处理和维护策略也是确保微调成功的关键因素。
FAQs
是否可以使用任何数据对大模型进行微调?
不可以,数据的质量和相关性直接影响微调后模型的性能,使用低质量或与任务无关的数据可能会导致模型学习错误的模式,从而降低其在特定任务上的表现。
微调大模型需要多少数据?
所需的数据量依据具体任务和模型的复杂度而定,一般而言,更多的数据可以帮助模型更好地学习和泛化,但也要考虑到计算资源的限制,理想的数据量应该能够覆盖所有必要的场景,同时又不至于引起过拟合。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/819286.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复