


在当今的信息化时代,数据库作为存储和管理数据的核心组件,其高可用性和可靠性对企业信息系统的重要性不言而喻,特别是分布式数据库系统,因其能够在多个物理位置上运行并处理大量数据的能力,成为了许多大型及中型企业的首选,DI(Dialog Interface)数据库作为一个分布式数据库系统,通过其分布式部署能够显著提升系统的可用性,本文将深入探讨DI数据库的分布式高可用部署策略,以及如何结合不同组件的特性来确保整个系统的稳定运行。
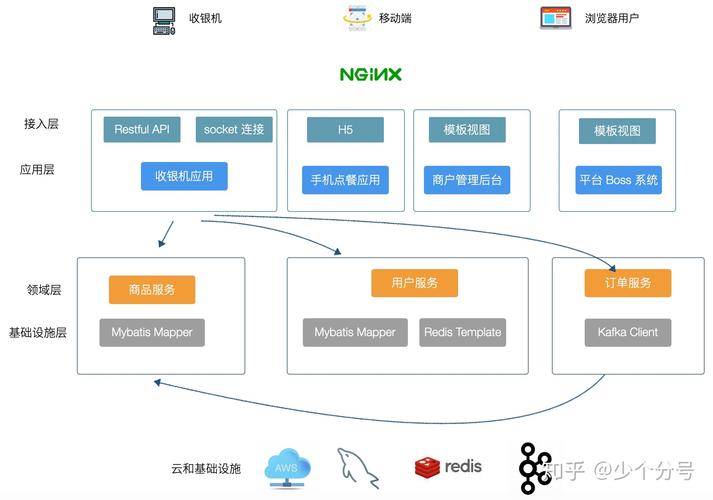

理解分布式数据库的基本架构是讨论其高可用部署的前提,类似于南大通用GBase 8c的分布式结构,DI数据库也可以采用包含协调器(CN)、数据节点(DN)、全局事务管理器(GTM)以及高可用(HA)管理组件等部分的架构,每个组件都扮演着特定的角色:CN负责SQL解析和优化,DN负责存储数据,GTM管理跨节点的事务,而HA组件则确保系统的高可用性。
探讨DI数据库分布式部署的高可用策略,一种常见的部署模式是“2+2+1”模式,这种模式下,即便一个机房发生故障,仍然有“2+1”个节点保持运行,形成多数派,从而将故障节点排除并继续提供服务,这种模式的优势在于它提供了故障转移能力,同时还能保持数据的一致性和系统的可用性。
还可以考虑使用YashanDB的yasboot运维工具来实现一键式部署,该工具支持多活部署的CN节点,每个节点都能独立工作并支持负载均衡;MN主备部署则通过至少一个主节点和两个备节点构建Raft集群,实现自动选主;DN的主备部署同样可以配置成1主1备的模式,确保数据的安全和可用性。
对于企业而言,选择合适的部署策略应基于自身的业务需求和资源情况,如果企业对数据库读写性能有较高要求,可以选择多活CN节点的部署方式,以实现负载均衡和高并发处理,而对于需要极高数据安全性的核心业务系统,则可以考虑采用更复杂的主备部署模式,如“2+2+1”或更高级别的冗余部署。
除了硬件和软件层面的部署策略外,还应注意数据库的日常维护和监控,利用消息队列服务如CMQ能够为分布式系统提供异步通信机制,保证信息传递的可靠性和高效性,定期的数据备份、恢复演练以及对系统性能的持续监控也是确保数据库高可用性的关键措施。
DI数据库的分布式高可用部署是一个涉及多方面技术和策略的综合体系,通过合理的架构设计、恰当的部署模式选择以及严格的运维管理,可以极大地提升数据库系统的稳定性和可用性,为企业的信息化建设提供坚实的数据支撑。
相关问答FAQs
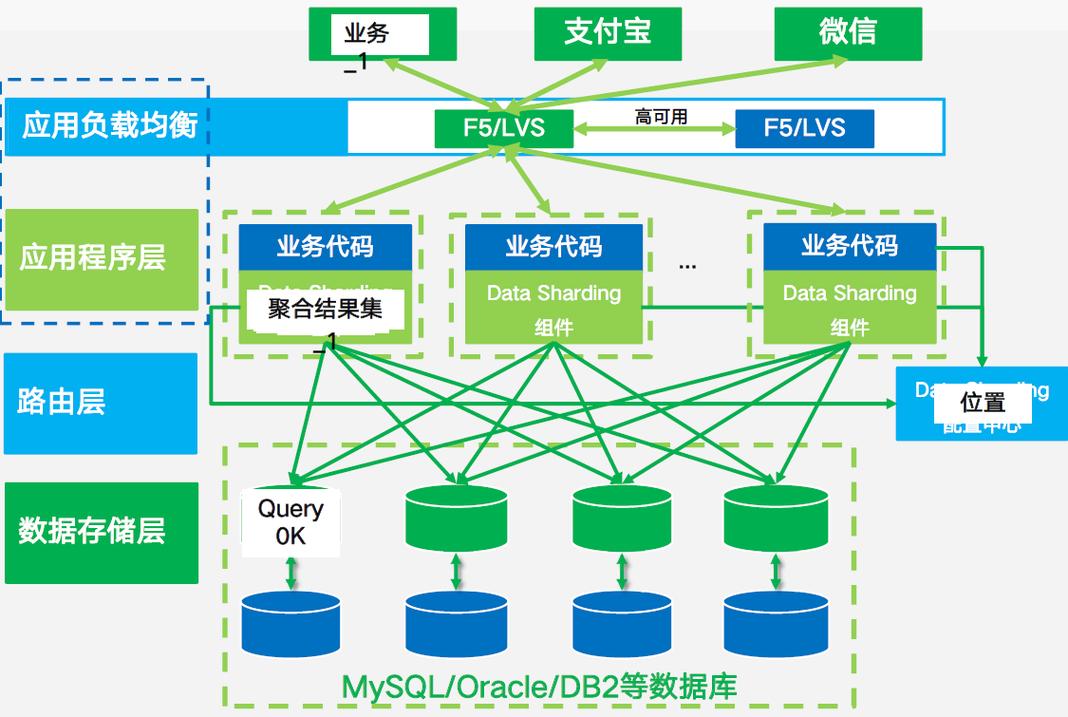
Q1: 分布式数据库部署中,什么是“2+2+1”模式?
A1: “2+2+1”模式是一种分布式数据库部署策略,其中数字代表不同角色的节点数量,在这种模式下,系统至少有2个协调器(CN)节点,2个数据节点(DN),以及1个全局事务管理器(GTM)节点,这种配置的好处在于即使一个机房发生故障导致其中一个节点失效,剩余的“2+1”节点仍能形成多数派,将故障节点排除并继续提供服务,从而保证了系统的高可用性和数据的一致性。
Q2: 如何选择合适的分布式数据库部署策略?
A2: 选择合适的分布式数据库部署策略应基于以下因素进行考虑:
业务需求:根据企业的业务特点和需求,确定对数据库的读写性能、数据一致性和可用性的要求。
资源情况:考虑企业的IT基础设施、预算和技术支持能力。
故障容忍度:明确企业能够接受的系统停机时间和数据丢失范围。
维护和监控:评估企业进行系统维护和监控的能力,包括数据备份、恢复操作和性能监控等。
综合这些因素后,企业可以选择最适合自身情况的部署策略,如多活部署、主备部署或采用特定的冗余部署模式。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/813363.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复