


MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,在Hadoop平台上,MapReduce通过将操作分为两个阶段:Map和Reduce来处理数据,下面通过几个实例来深入理解MapReduce的编程方式和实际应用。
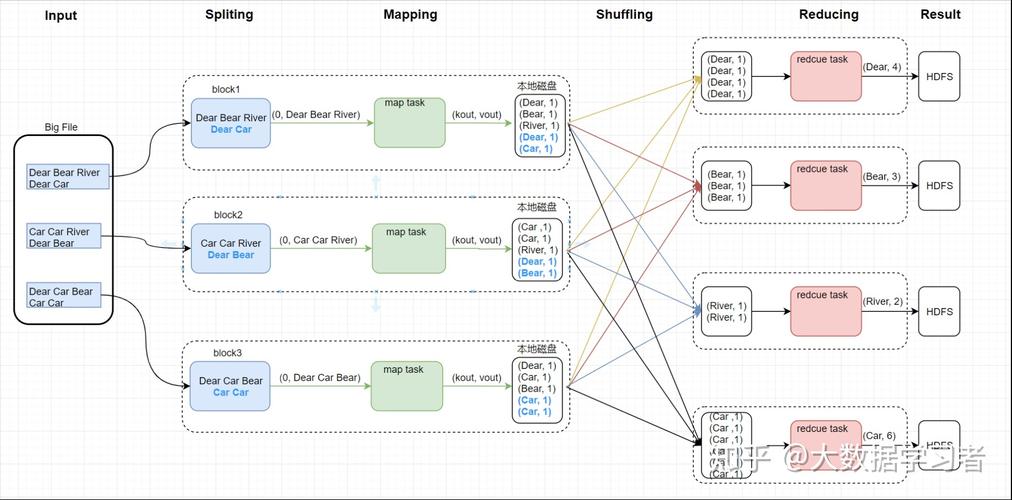

1、单词计数
原理解析:这是最基础的MapReduce应用,它统计文本中各单词的出现次数,Map函数读取文本文件并将其分割成单词,然后为每个单词生成一个键值对(单词,1),Reduce函数则将所有相同的单词键值对进行合并,并计算总数。
代码实现简述:在Map部分,读取文件行并拆分单词,为每个单词输出(单词,1),在Reduce部分,对相同键的值进行迭代求和。
2、反向索引
原理解析:反向索引用于快速找到包含某个词的所有文档,在Map部分,每个文档被分配一个唯一的文档ID,并为文档中出现的每个单词创建一个(单词,文档ID)的键值对,在Reduce部分,将所有具有相同单词的文档ID聚集到一起。
代码实现简述:Map函数输出每个出现的单词及其对应的文档ID;Reduce函数收集所有相同单词的文档ID列表。
3、去重统计
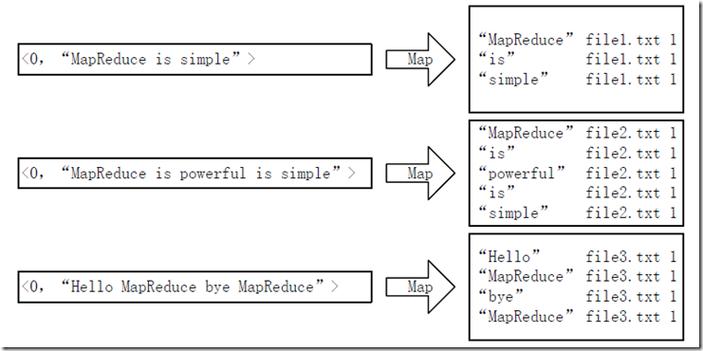
原理解析:在社交网络分析中,需要确定有多少独立的朋友关系,如果两次数据中朋友关系可能颠倒(如joe是jon的朋友,同时jon也是joe的朋友),需要进行去重处理。
代码实现简述:Map函数为每对朋友关系生成一个键值对,而Reduce函数负责去除重复的关系对。
4、分布式grep
原理解析:grep是Unix系统中的一个工具,用于文本搜索,在MapReduce中实现grep可以并行地在多台机器上搜索大型文件系统中符合特定模式的行。
代码实现简述:Map函数搜索符合模式的行并输出;Reduce函数仅传递Map的输出结果。
5、排序
原理解析:在处理大数据时经常需要对数据进行排序,Map函数为其输入数据产生键值对,并进行本地初步排序,Reduce函数则接收这些预排序的键值对,执行最终的归并排序。
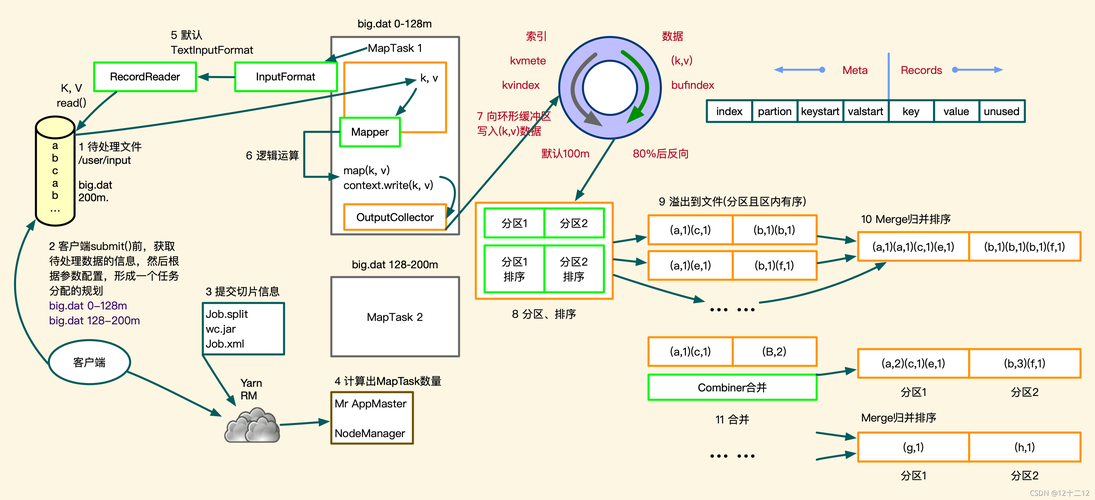
代码实现简述:Map部分写入(关键字,值)对,并在本地进行排序;Reduce部分则完成最后的归并操作。
6、高级聚合
原理解析:除了基本的Map和Reduce之外,复杂的数据分析任务可能需要多个阶段的MapReduce作业,第一个MapReduce作业的输出可以作为第二个作业的输入。
代码实现简述:配置和链式多个MapReduce作业,每个作业处理前一个作业的输出作为其输入。
7、图算法的实现
原理解析:MapReduce可以用于实现图算法,比如计算网页的PageRank值,Map任务初始化或更新顶点的值,Reduce任务则负责组合和处理这些值以更新图的结构。
代码实现简述:Map函数处理图的顶点并更新其权重,Reduce函数负责整合这些信息以重新计算图结构。
8、文本模式匹配
原理解析:在大量文本数据中查找特定模式或正则表达式的匹配项,Map函数扫描数据识别匹配项,Reduce函数则汇归纳果。
代码实现简述:Map部分对输入文本应用正则表达式匹配并输出匹配项,Reduce部分汇总和输出最终结果。
在编写和优化MapReduce作业时,需要注意数据的序列化和反序列化、合理设置Map和Reduce任务的数量以及考虑网络带宽和存储容量等限制因素,通过上述实例可以看出,MapReduce虽然只包含Map和Reduce两个阶段,但它能够灵活处理各种类型的数据处理任务。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/813077.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复