



在云计算时代,大数据处理的需求日益增长,而Hadoop作为一种开源的分布式计算框架,为处理大规模数据集提供了强大的支持,本文旨在详细介绍如何在云平台上部署和利用弹性MapReduce (EMR) 服务,以及如何通过开源服务包规范来实现安全、低成本、高可靠的云端Hadoop服务。
EMR平台
基本介绍
定义:EMR是一种基于云原生技术和泛Hadoop生态开源技术的大数据分析服务平台。
核心优势:提供易于部署及管理的服务,支持多种开源大数据组件如Hive、Spark等。
功能特点
可伸缩性:根据数据处理需求自动扩展或缩减资源。
安全可靠:采用先进的数据加密和访问控制机制。
成本效益:按需付费模式,无需前期重投资。
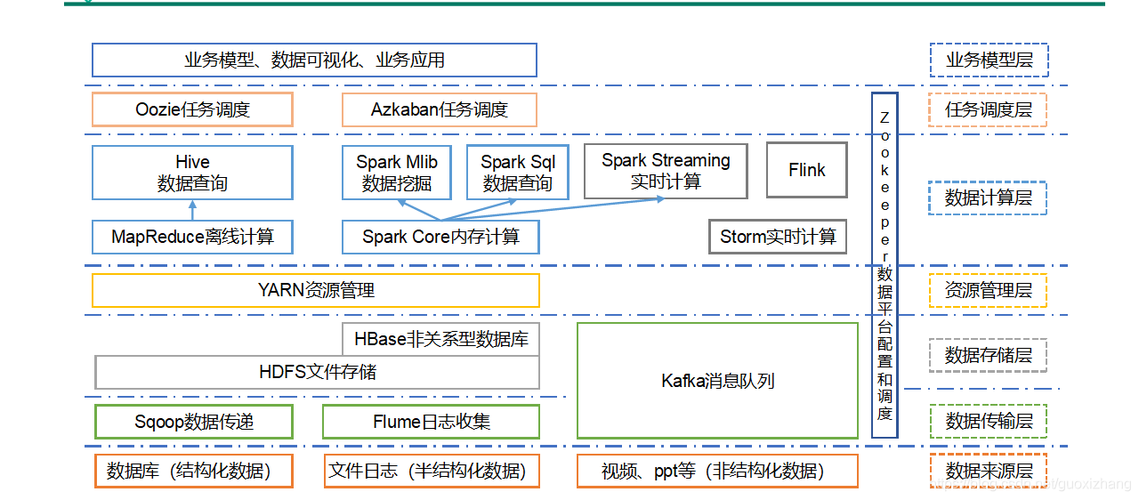
技术架构
数据湖构建:助力企业在云端高效构建企业级数据湖。
组件集成:整合HBase、Flink等多种数据处理组件。
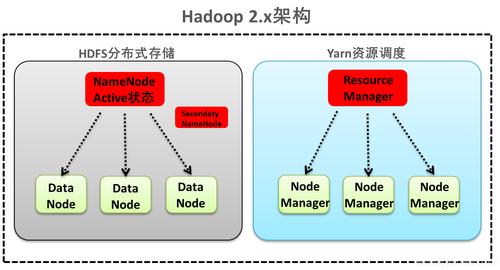
Hadoop集群搭建与配置
准备工作
环境预置:确保所有实验环境预先配置完成并经过测试。
基础设定:购买并配置云服务器,获取必要的安全认证信息。
搭建步骤
ECS配置:购买并设置云服务器作为Hadoop集群的节点。
OBS服务:使用对象存储服务来存放大量数据,实现数据的云端读写。
实践操作
手动搭建:在云服务器上手工安装和配置Hadoop环境。
验证过程:通过构建Spark集群等方式验证集群的配置和性能。
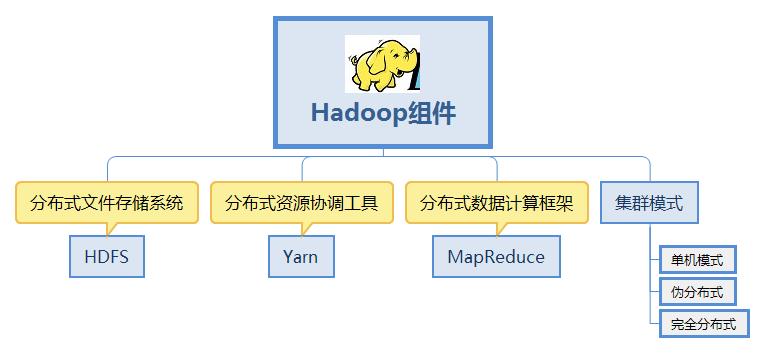
关键开源组件和服务
Data Processing
Hive:建立在Hadoop之上的数据仓库工具,用于数据汇总和分析。
Spark:高速大数据处理引擎,适用于实时数据处理和机器学习任务。
Storage Management
HDFS:分布式文件系统,用于存储大规模数据集,具有高可靠性和容错性。
Alluxio:提供统一数据访问层,优化数据在不同存储间移动的性能。
Performance Optimization
StarRocks:用于数据仓库的高性能列式存储引擎。
Iceberg:提供表格格式和用于大型数据集的即时查询和更新操作的系统。
安全性与合规性
数据安全
加密技术:数据传输和存储过程中均采用强加密措施。
权限管理:严格的访问控制和身份验证机制,确保数据只能被授权用户访问。
法规遵守
数据保护法遵循:符合GDPR等国际数据保护法规要求。
审计与监控:提供详尽的日志记录和监控系统,便于追踪数据使用和修改情况。
成本管理与优化
成本效益分析
按需付费:用户按照实际使用的资源量付费,有效控制成本。
资源优化建议:根据使用情况提供资源配置优化建议,以降低成本。
资源调度
自动伸缩:根据负载自动调整资源,避免资源浪费。
细粒度计费:提供细粒度资源使用情况,帮助用户精确控制费用。
后续维护与发展
持续支持
定期更新:定期更新EMR服务,引入最新功能与性能改进。
社区互动:积极参与开源社区,与全球开发者共同推动项目进步。
未来展望
技术前沿:探索AI与大数据的深度融合,开拓数据处理新领域。
行业解决方案:开发更多行业特定的大数据解决方案,满足多样化的业务需求。
通过上述详细解析,我们可以看到弹性开源Hadoop服务不仅提供了一种灵活、安全且高效的数据处理方式,还带来了丰富的技术生态和社区支持,借助这些先进的开源技术和服务规范,企业能够更好地构建和管理其数据架构,进而提升竞争力和市场响应速度。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/811663.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复