


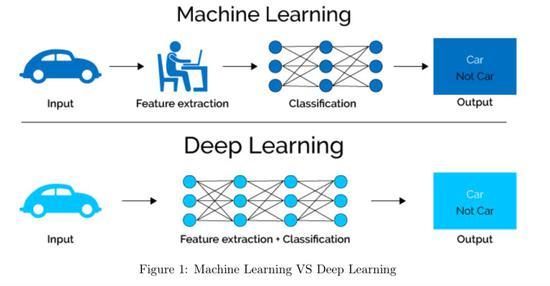

机器学习作为一种强大的数据分析工具,在众多领域中显示出其巨大的潜力和应用价值,端到端的机器学习场景涉及到从原始数据的输入到最终结果的输出整个流程,本文旨在通过详细阐述这一过程的各个环节,帮助读者构建起对机器学习项目实施的全面认识。
观察大局是启动任何机器学习项目的首步,这一阶段主要是确定问题的类型,比如是进行数据分类、预测还是聚类等,明确目标后,接下来便是获得相关的数据,数据获取可以通过多种途径,如公开数据集、API服务或直接从用户处收集。
数据的质量直接影响模型的性能,因此数据探索和可视化是不可或缺的一步,在这一阶段,数据科学家通常会进行数据清洗、特征工程以及初步的数据可视化,以便更好地理解数据的特性和结构,图像分类任务中,数据标注的准确性将直接影响模型的学习效果。
接下来是模型训练,这是机器学习中核心的部分,选择合适的算法和训练模型,依赖于问题的具体需求和数据的特性,训练过程中要不断地调整参数,验证模型的效果,并进行必要的优化,模型的评估也极为关键,通常包括交叉验证、准确率评估等多种方法来确保模型的泛化能力。
之后是将训练好的模型部署为服务,这一步涉及将模型集成到生产环境中,确保其稳定运行并能够处理实时的数据请求,部署后的模型需要持续监控其性能,根据反馈进行迭代更新以适应可能的数据变化和新的业务需求。
对整个项目进行回顾归纳,分析哪些环节可以进一步优化,积累经验教训以指导未来的项目。
值得注意的是,在整个端到端的过程中,版本控制和项目管理的工具也扮演着重要的角色,它们帮助团队有效地协作,管理各种资源和进度,确保项目的顺利进行。
通过以上详尽的步骤解析,我们可以看到,一个端到端的机器学习项目远不止是简单的数据输入和模型输出,而是一个涉及多个环节、需要多方面技能综合运用的复杂过程,每一个成功的机器学习应用背后都有严格的项目管理、精细的数据处理、恰当的模型选择和周密的部署计划。
机器学习项目的成功不仅取决于技术层面的优化,更在于对问题的深刻理解和全过程的周密管理,通过这种端到端的视图,可以更好地把握机器学习项目的全局,从而有效地解决实际问题,推动相关技术的发展和应用。
FAQs
1. 如何选择合适的机器学习算法?
选择合适的机器学习算法主要依据问题的类型(如分类、回归等)和数据的特征(如数据大小、特征数量等),了解不同算法的优缺点和适用情况也是必要的,对于具有大量特征和相对小数量样本的数据集,SVM可能是一个好的选择;而对于高维度和大规模数据集,神经网络可能表现更好。
2. 机器学习项目中常见的挑战有哪些?
机器学习项目中常见的挑战包括数据质量问题、模型过拟合或欠拟合、计算资源限制等,数据质量直接影响模型效果,因此在数据预处理阶段需要进行严格的数据清洗和特征工程,过拟合和欠拟合是模型训练中经常遇到的问题,适当的交叉验证和正则化技术可以帮助缓解这些问题,大规模的机器学习模型训练需要大量的计算资源,合理配置和使用云计算资源是解决这一问题的有效途径。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/807765.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复