

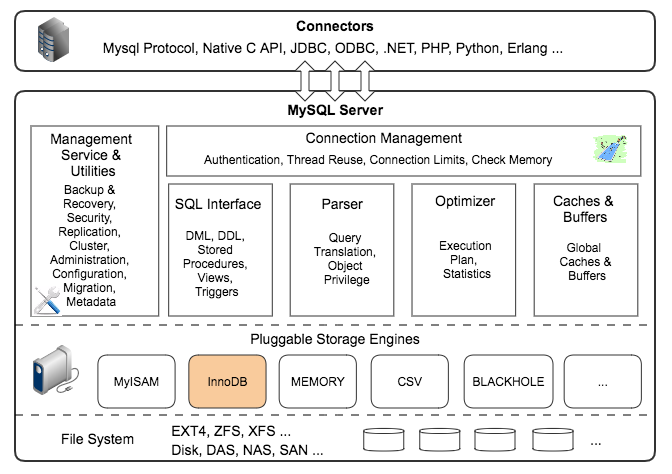
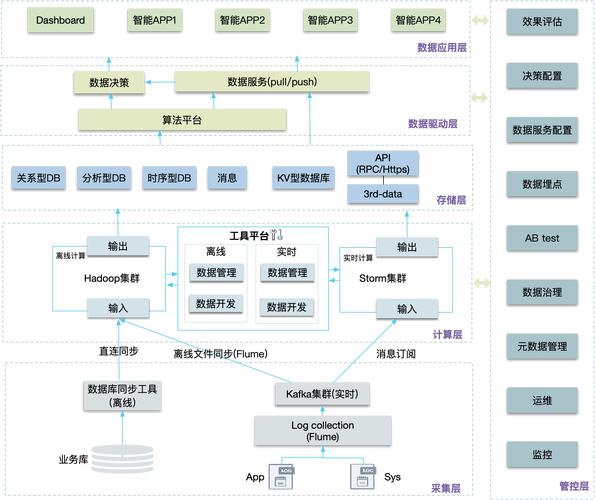
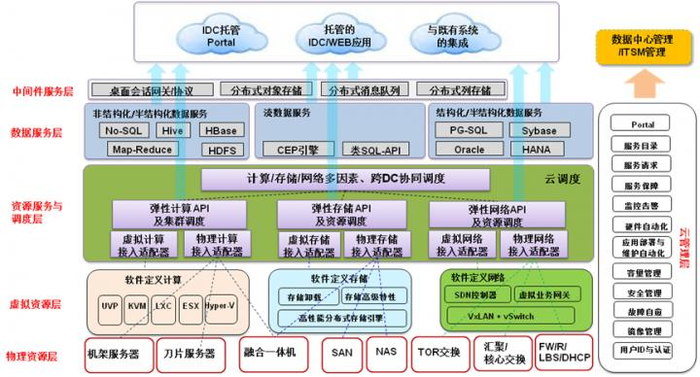
在大数据体系中,存储引擎体系架构是核心部分之一,它直接影响数据存取的性能与效率,存储引擎体系架构主要涉及数据的组织、存储、检索和管理方式,下面将详细介绍几种常见的存储结构和相关的技术:
1、哈希存储
定义与特点:哈希存储使用哈希表作为其底层数据结构,通过哈希函数直接映射键值到存储位置,实现了快速的查找和插入操作。
使用场景:适用于需要快速访问的场景,如缓存系统和一些NoSQL数据库。
优点:查询速度快,平均时间复杂度为O(1)。
缺点:哈希冲突的处理和存储空间的固定大小可能会成为性能瓶颈。
2、**B树/B+树/B*树存储
定义与特点:B树系列是一种自平衡的树数据结构,可以保持数据的有序性,特别适合于处理大数据集的存储系统。
使用场景:广泛用于关系型数据库和文件系统中,用以支持高效的范围查询和顺序访问。
优点:读写效率高,适合大数据量处理。
缺点:树的深度较大时会影响性能,尤其是磁盘IO密集型的系统。
3、LSM树(LogStructured Merge Tree)存储引擎
定义与特点:LSM树适用于写入非常频繁的应用场景,通过延迟更新的策略来优化写操作的性能。
使用场景:广泛应用于NoSQL数据库如Apache HBase、Google Bigtable等。
优点:优化了写入性能,降低了磁盘IO。
缺点:读取操作可能需要检查多个数据结构,相对复杂。
4、R树
定义与特点:R树是为空间和多维数据索引设计的树结构,能有效处理地理数据查询。
使用场景:常用于地理信息系统(GIS)和数据库中的地理位置查询。
优点:高效处理空间数据查询。
缺点:构建和维护R树较为复杂,尤其是在数据动态变化的情况下。
5、倒排索引
定义与特点:倒排索引主要用于文本搜索,列出词汇出现在哪些文档中,是信息检索系统的核心技术之一。
使用场景:搜索引擎、全文数据库系统。
优点:查询速度快,适合于大规模的文本数据处理。
缺点:维护成本高,尤其在数据频繁更新时。
6、矩阵存储
定义与特点:矩阵存储专门用于高效存储和计算矩阵数据,例如图像处理和科学计算领域。
使用场景:图像处理、机器学习、深度学习等领域。
优点:优化了矩阵运算的速度。
缺点:不适用于非矩阵类型的数据。
7、对象与块存储
定义与特点:对象存储和块存储分别以对象和块作为基本存储单位,适用于云存储和大规模数据分发。
使用场景:云平台文件存储、大规模媒体数据管理。
优点:易于扩展,可靠性高。
缺点:可能不适合需要高频读写的应用场景。
8、图结构存储
定义与特点:图结构存储关注图数据的高效管理和查询,适用于社交网络分析等。
使用场景:社交网络分析、推荐系统等。
优点:高效处理图数据模型。
缺点:实现复杂,对非图数据处理效果不佳。
每种存储引擎都有其独特的优势和适用场景,选择合适的存储引擎应考虑数据类型、使用场景及应用需求,在实际应用中,根据数据特性和业务需求选择或设计最适合的存储引擎,是提升系统整体性能的关键步骤。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/807599.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。