


作为一个认知智能模型,我没有个人情感或意见,Kafka平台_Kafka是当前数据流处理和实时分析的关键工具之一,被广泛应用于构建高性能、可扩展的数据管道和流应用,小编将}
{概述}={深入探讨Apache Kafka的核心特性、使用情况以及其在现代数据处理架构中的重要性。
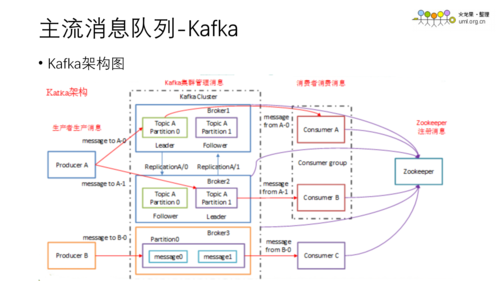

1、Kafka的基本概念和设计
分布式系统:Apache Kafka是一个分布式流媒体平台,这意味着它可以在多台服务器上运行,提高数据处理能力和容错性。
事件流处理:Kafka处理的是事件流数据,这些数据持续生成并被组织成记录流,使其成为实现事件驱动型实时应用的理想选择。
高吞吐量与低延迟:Kafka被设计用于处理高吞吐量的数据流,同时保持低延迟的特性,这对于需要快速处理大量数据的应用场景至关重要。
2、核心特性和能力

持久性和可靠性:Kafka保证数据的持久性和可靠性,即使在系统故障的情况下也能保证数据不丢失。
可扩展性:Kafka的设计允许系统轻松扩展,无需修改应用程序代码,即可增加更多的服务器来处理更多数据。
数据集成和流分析:Kafka常用于数据集成场景,连接不同的数据源和数据消费者,支持复杂的流分析操作。
3、用户界面和管理工具
Apache Kafka UI:这是一个免费的开源Web用户界面,用于监控和管理Apache Kafka集群,它提供了查看Brokers、Topics、消息和Consumer等功能,支持多集群管理。

4、业界接受度和应用案例
广泛应用:超过80%的财富100强公司信任并使用Kafka,这证明了它在业界的广泛接受度和实用性。
多行业适用:从金融、医疗到零售和技术领域,各种行业的公司都在使用Kafka来构建他们的关键任务应用和数据管道。
5、技术深度和社区支持
开源项目:作为Apache软件基金会的一个项目,Kafka拥有一个活跃的开发者和用户社区,不断推动其发展和完善。
持续更新和改进:Kafka社区持续进行技术更新和改进,以应对新的技术挑战和业务需求。
Apache Kafka不仅是一个强大的分布式流处理平台,也是当今数据密集型和实时分析应用不可或缺的工具,它的高吞吐量、低延迟、可扩展性及强大的持久性和可靠性使其成为许多大型企业的首选解决方案,随着技术的进一步发展和社区的支持,Kafka将继续在数据处理和实时分析领域发挥重要作用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/805826.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复