


Kafka是一个分布式数据流平台,经常被用于处理实时数据馈送,它具有强大的消息传递能力,支持多消费者,并能在机器故障时保证容错能力,小编将}
{概述}={深入了解Kafka的核心概念和如何搭建一个Kafka流式数据处理集群。


核心概念和基本架构
1、消息和主题
Kafka基于发布/订阅模型工作,消息是数据的载体,主题则是消息的类别或通道。
生产者发送消息到特定主题,消费者从这些主题订阅并处理消息。
2、分区和副本
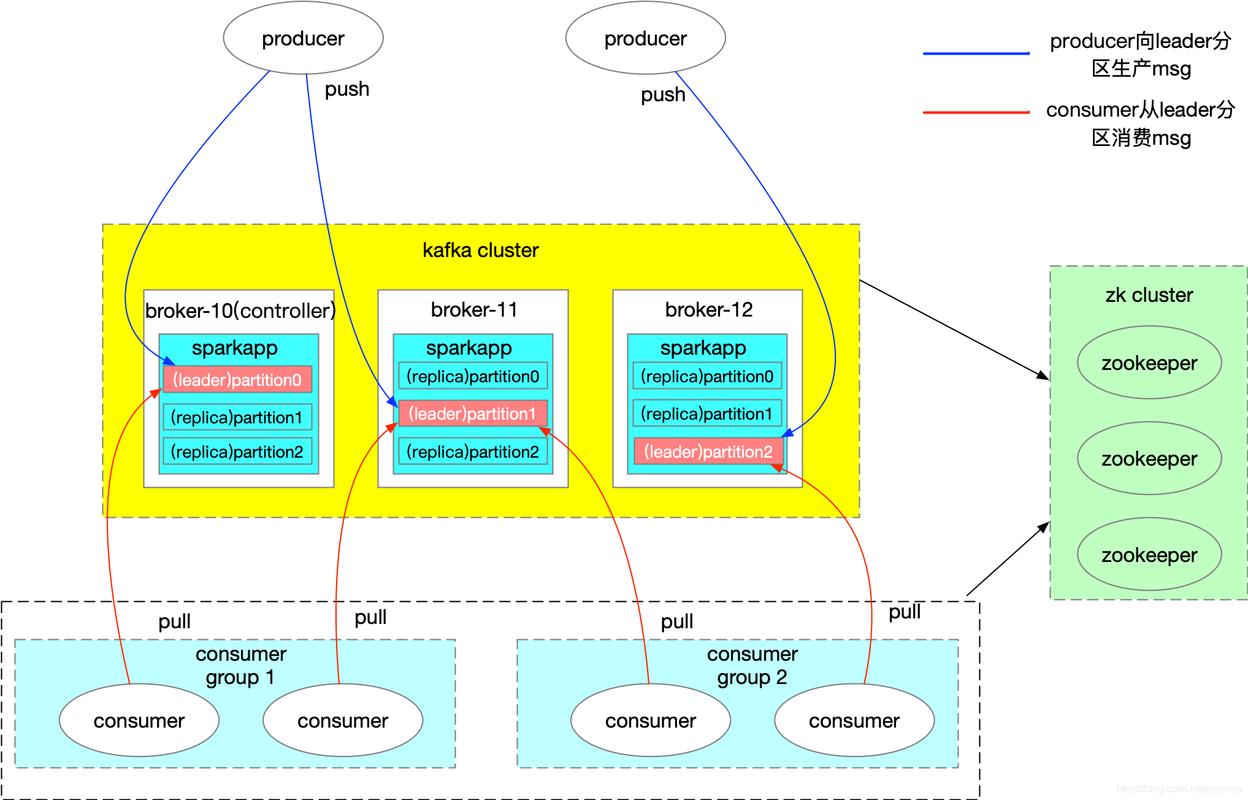
分区允许主题分布在多个服务器上,实现并行处理,每个分区可以有多个副本以提高可用性和容错能力。
副本中的一个被选为领导者,负责处理所有的读写请求,而其他副本同步领导者的数据以备不时之需。
3、生产者和消费者
生产者将数据推送到Kafka主题。
消费者从主题拉取数据进行处理,消费者可以属于消费者群组,共享负载均衡。

4、 broker和集群
Kafka服务器称为broker,一个Kafka集群由多个broker组成,提高系统的整体性能和容错能力。
Broker不仅存储消息,还负责消息的传播。
Kafka集群搭建步骤
1、环境准备
选择合适的操作系统,如CentOS 6.5,确保系统的稳定性与兼容性。
安装Java环境,因为Kafka是使用Java开发的,需要JDK 1.8或以上版本。
2、安装Kafka和Zookeeper
Zookeeper是Kafka管理集群的必要工具,先安装Zookeeper。
下载并解压缩Kafka,设置必要的环境变量。
3、配置
编辑Kafka配置文件server.properties,设置broker的ID、监听的端口等。
配置log目录,确保有足够的空间存储消息。
4、启动集群
首先启动Zookeeper。
接着启动Kafka服务器,可以通过单个或多个broker启动脚本来初始化整个Kafka集群。
5、测试
使用Kafka提供的命令行工具创建主题,发送和接收消息进行测试。
观察broker和Zookeeper的日志文件,确认系统运行无误。
通过上述的详细步骤,可以搭建一个基本的Kafka流式数据处理集群,在操作过程中,注意各服务的配置正确性以及系统资源的合理分配,完成这些步骤后,即可进入更高级的配置和优化阶段,例如设置安全性、监控和性能调优等。
Apache Kafka因其独特的分布式特性和高效的数据处理能力,在大数据实时处理领域占据了重要地位,了解其核心概念和掌握搭建高效集群的能力对于任何希望处理大规模实时数据流的组织都是极其重要的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/805673.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复