


python,from pyspark.sql import SparkSession,,spark = SparkSession.builder , .appName("Connect to MRS Spark") , .getOrCreate(),,# 读取数据,df = spark.read.csv("path/to/your/data.csv", header=True, inferSchema=True),,# 显示数据,df.show(),`,,请确保将path/to/your/data.csv`替换为实际的数据文件路径。在当今的大数据时代,云数据库和数据处理已成为企业与开发者日常操作的重要部分,MRS Spark作为一个基于Apache Spark的大数据处理服务,提供了强大的数据存储和分析能力,小编将}
{概述}={详细探讨如何使用PySpark连接MRS Spark集群,并利用其强大的数据处理能力:
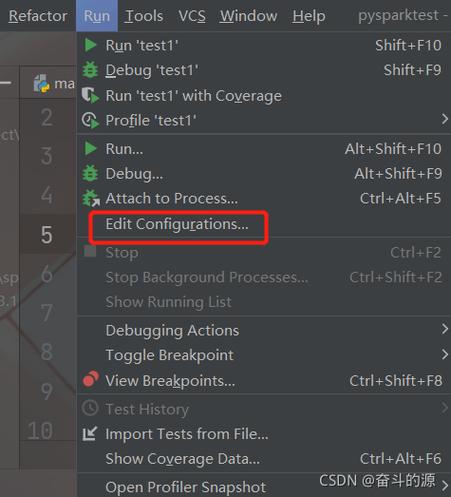

1、配置Spark集群环境
基础环境搭建:部署PySpark环境是连接和使用MRS Spark的前提,根据"Spark重温笔记(一):一分钟部署PySpark环境"的介绍,可以了解到如何轻松上手Spark配置,包括pyspark环境的配置、运行模式的选择等。
安全性设置:对于内网开启Kerberos认证的MRS Spark集群,需要对Spark的配置文件进行相应的修改,如设置"spark.yarn.security.credentials.hbase.enabled"为true,这是保障连接安全的必备步骤。
2、使用JDBC连接云数据库
配置JDBC驱动:在PySpark中连接MySQL数据库或其他类型的数据库,一种常见的方式是通过JDBC,这要求下载对应数据库的JDBC驱动程序,并将其添加到Spark的类路径中,具体操作是将JDBC驱动程序,例如mysqlconnectorjava8.0.26.jar复制到$SPARK_HOME/jars目录,这样Spark就能识别并使用这个驱动来连接数据库。
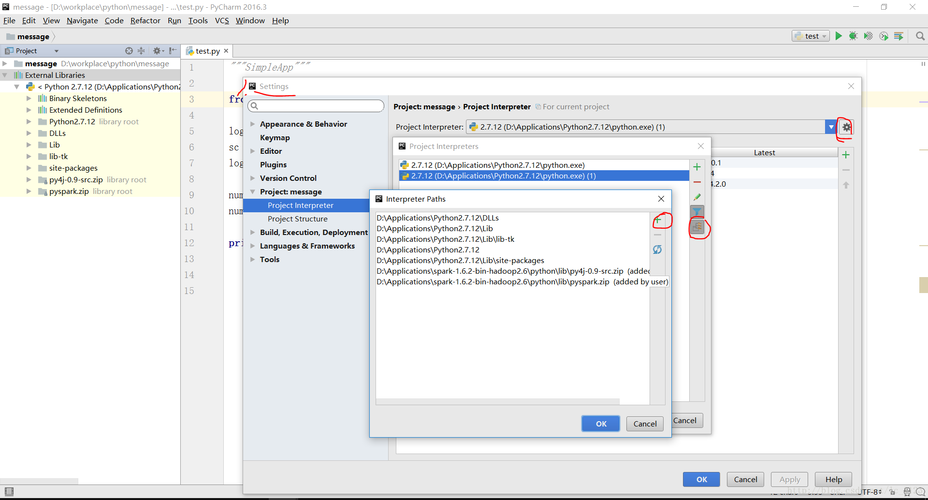
3、通过PySpark连接到Spark集群
本地开发环境连接:从本地Jupyter Notebook连接到Spark集群是一种常见的开发模式,通过设置相关的Spark连接参数,可以实现在本地开发环境中对远程Spark集群的操作。
4、使用Spark SQL访问数据
数据提取与处理:Spark SQL是处理大规模数据集的强大工具,它支持从不同的数据库中提取数据,并进行处理,可以使用MRS Spark SQL访问如GaussDB(DWS)这样的数据仓库,进行数据的提取和分析。
5、实际操作示例
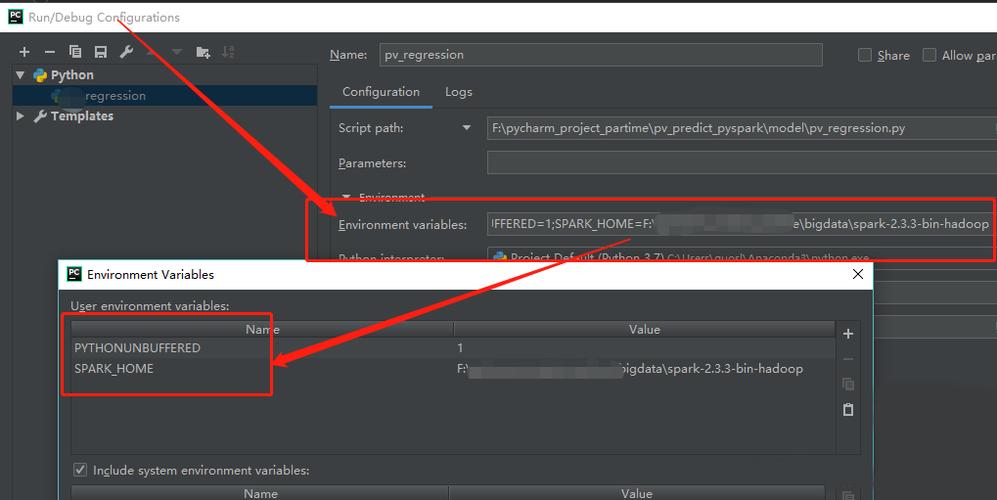
提交Spark任务:在配置好环境与安全设置后,可以通过sparksubmit命令提交任务至MRS Spark集群进行处理,使用参数如master yarn指定资源管理器,keytab与principal用于Kerberos身份验证,这是执行数据分析任务的标准流程。
在深入探讨如何利用PySpark连接和使用MRS Spark的同时,还需要考虑以下因素和注意事项,以确保整个过程的顺利进行:
确保所有配置文件的设置均正确无误,避免因配置错误导致无法连接或数据访问异常。
安全性设置是保护数据传输和访问安全的重要环节,正确配置Kerberos可以为数据传输提供一层安全保障。
选择合适的运行模式和部署模式,这对于优化性能和资源配置非常关键。
使用PySpark连接MRS Spark涉及环境配置、安全性设置、数据库连接以及任务提交等多个环节,每一步都需要精确操作和细心配置,以确保数据处理任务的高效执行。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/805298.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复