



在数字化和网络化日益深入的今天,数据隐私与安全成为了全球关注的焦点,可逆数据隐藏技术作为一种既能保护数据隐私也能确保数据完整性的方法,其在机器学习领域的应用尤为引人注目,本文将深入探讨这一技术在机器学习端到端场景中的最新应用情况。
技术原理
可逆数据隐藏技术是一种先进的信息隐藏方法,它允许在不损坏原始数据的前提下,在其中嵌入其他信息,这项技术的核心在于其“可逆性”,即隐藏的信息可以在必要时完整无损地提取出来,同时恢复原始数据至其原始状态。
应用场景
随着人工智能和机器学习技术的发展,可逆数据隐藏找到了新的应用领域,特别是在数字图像处理和信息安全领域,深图隐藏(Deep Image Hiding)利用深度学习模型在图像中嵌入信息,此过程不仅保留了图像的视觉质量,还确保了嵌入信息的安全。
最新研究
HiNet项目引起了研究者的关注,该项目由北京航空航天大学的研究团队提出,专注于开发可逆网络,用于高效且安全的数据隐藏,HiNet利用复杂的算法,使得数据隐藏过程不仅更加隐蔽,还能在需要时快速准确地恢复原始数据。
实际案例
华为云在其平台上实施了可逆数据隐藏技术,以增强云存储数据的安全性,通过这种方式,用户可以放心地存储敏感信息,在需要时再将其提取出来,大大增强了数据处理的灵活性和安全性。
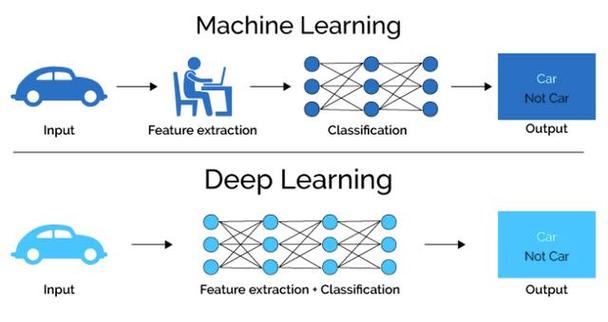
技术挑战与未来趋势
尽管可逆数据隐藏技术具有明显的优势,但在机器学习应用中仍面临一些挑战,包括如何处理大规模数据集的隐藏与恢复、如何提高隐藏数据的比率与安全性等,未来的研究可能会集中在优化算法、提升效率及扩大应用范围等方面。
可逆数据隐藏技术在保护数据隐私和完整性方面显示出巨大的潜力,特别是在机器学习的端到端场景中,随着技术的不断进步和应用的深入,预计将在更多领域展现其独特价值。
可逆数据隐藏技术通过在不损害原始数据的情况下隐藏信息保证了数据的隐私性和完整性,这种技术在机器学习领域尤其有前景,从深图隐藏到云计算平台的应用,都显示了其广泛的应用潜力和重要性,随着技术的进一步发展,可逆数据隐藏将在数据安全领域扮演越来越重要的角色。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/804362.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复