


在当今这个信息爆炸的时代,大数据挖掘与机器学习技术的结合已成为企业竞争力的新引擎,下面将详细探讨大数据挖掘中决策树(DT)机器学习的端到端场景:
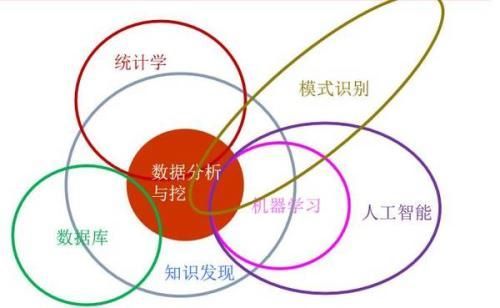

1、数据预处理
数据清洗:处理缺失值、异常值和噪声数据。
特征选择:筛选出对模型预测最有帮助的特征。
数据转换:将数据处理成可供模型学习的格式。
2、模型选择
算法评估:分析不同算法的适用性和性能。
参数调优:通过网格搜索等方法寻找最优参数组合。
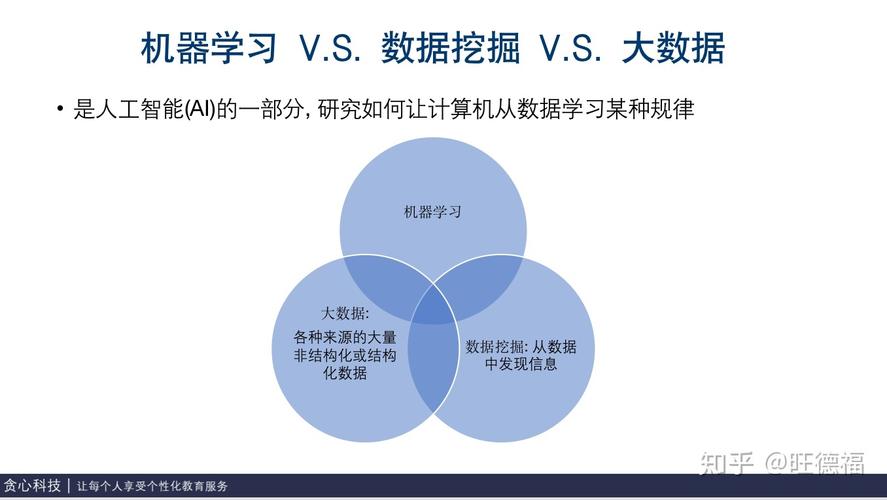
交叉验证:使用交叉验证技术评估模型的泛化能力。
3、决策树模型训练
构建树结构:递归地分裂数据,形成树状结构。
剪枝优化:通过剪枝防止过拟合,提高模型泛化能力。
模型评估:计算模型的准确率、召回率等评估指标。
4、模型应用与部署
实时预测:将模型应用于实时数据流进行预测。

模型监控:持续监测模型性能,确保稳定性。
反馈迭代:根据实际应用效果调整和优化模型。
5、数据分析与报告
结果解释:解释模型预测结果的业务意义。
可视化展示:通过图表等形式直观展示分析结果。
决策支持:为业务决策提供数据支持和建议。
6、性能优化与维护
模型更新:定期更新模型以适应新的数据趋势。
硬件优化:优化模型运行的硬件环境,提高效率。
软件升级:升级相关软件和工具,保持技术的先进性。
7、案例研究与实践经验
成功案例:分析行业内成功的决策树应用案例。
常见陷阱:归纳在决策树应用过程中可能遇到的问题。
经验分享:交流实践经验,提升行业整体水平。
8、未来趋势与挑战
技术发展:探索新技术在决策树模型中的应用前景。
数据隐私:在保证数据隐私的前提下进行数据挖掘。
伦理法规:关注机器学习领域的伦理和法律问题。
在大数据挖掘与机器学习领域,决策树作为一种基础且强大的模型,其端到端的应用涉及到从数据预处理到模型部署等多个环节,每个环节都有其关键任务和技术要点,如数据清洗、特征选择、模型训练、实时预测等,通过对这些环节的深入理解和精细操作,可以大幅提升模型的性能和应用价值,随着技术的不断进步和数据环境的日益复杂,决策树模型的应用也面临着新的挑战和机遇,需要从业者不断学习和创新,以适应这一动态发展的领域。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/803494.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复