


大数据与大容量数据库


在当今信息时代,数据已经成为了企业和组织最宝贵的资源之一,随着互联网、物联网和各种智能设备的普及,数据的产生速度和规模已经远远超出了传统数据库处理能力的范围,这就催生了大数据技术和大容量数据库的发展,本文将探讨大数据的概念、特点以及大容量数据库的相关知识。
大数据的定义
大数据通常指的是那些传统数据处理应用软件难以处理的大规模和复杂的数据集,它涉及到数据的采集、存储、管理、分析直到信息的呈现,根据国际数据公司(IDC)的定义,大数据具有四个主要特征,即“4V”:体量大(Volume)、速度快(Velocity)、种类多(Variety)和价值密度低(Value)。
大数据的特点
体量大:数据量级从TB到PB不等,甚至更大。
速度快:数据以极快的速度生成和流动,例如社交媒体更新、在线交易记录等。
种类多:包括结构化数据、半结构化数据和非结构化数据。
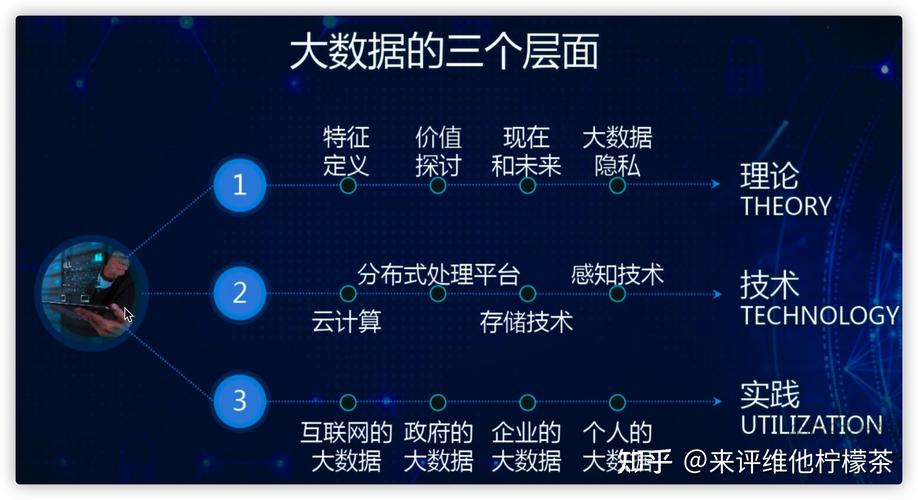
价值密度低:虽然数据量巨大,但并非所有数据都是有价值的,需要通过分析提取有用信息。
大容量数据库的类型
为了应对大数据的挑战,出现了多种类型的大容量数据库技术,主要包括:
1、NoSQL数据库:非关系型数据库,如MongoDB、Cassandra、DynamoDB等,它们能够横向扩展,适应非结构化或半结构化数据。
2、列式存储数据库:如Google BigTable, Apache HBase,它们优化了读写操作,特别适合于处理大量数据。
3、NewSQL数据库:结合了NoSQL的可扩展性和传统关系型数据库的事务性,如Google Spanner、CockroachDB。
4、分布式文件系统:如HDFS(Hadoop Distributed File System),用于存储大规模数据集。
5、数据仓库:如Amazon Redshift、Google BigQuery,专为数据分析和商业智能设计。
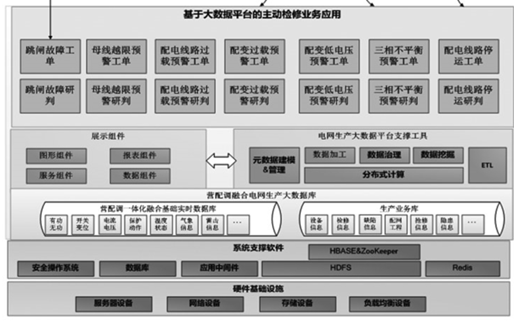
大数据处理流程
大数据的处理流程通常包括数据采集、数据存储、数据处理和数据分析四个阶段,每个阶段都需要相应的技术支持:
数据采集:使用日志收集系统如Flume、Kafka等。
数据存储:使用上述提到的大容量数据库和分布式文件系统。
数据处理:使用批处理系统如Hadoop MapReduce,流处理系统如Spark Streaming。
数据分析:使用BI工具、机器学习库等进行数据挖掘和预测分析。
相关技术趋势
随着技术的不断进步,大数据领域也在不断发展,实时数据处理变得越来越重要,云服务使得大数据技术更加易于访问和使用,机器学习和人工智能的结合为数据分析带来了新的可能。
FAQs
Q1: 大数据和大容量数据库有什么区别?
A1: 大数据是一个广义的概念,它指的是无法用传统数据库工具有效处理的庞大数据集,而大容量数据库是大数据处理中的一种技术解决方案,旨在存储和处理大规模的数据。
Q2: 为什么传统的关系型数据库不适合处理大数据?
A2: 传统的关系型数据库在设计时没有考虑到如今的数据量级和速度,它们在处理体量大、速度快的数据时会遇到性能瓶颈,同时对于非结构化数据的处理也不够灵活,在大数据场景下,更适合使用NoSQL、NewSQL等新型数据库技术。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/802535.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复