

在当今信息化社会,汉字的存储方式对于计算机系统和网络传输至关重要,汉字作为一种象形文字,其编码和存储比基于字母的西方文字要复杂得多,本回答旨在详细阐述存储一个汉字所需的字节数,并从多个角度分析该问题,以确保理解全面且深入。
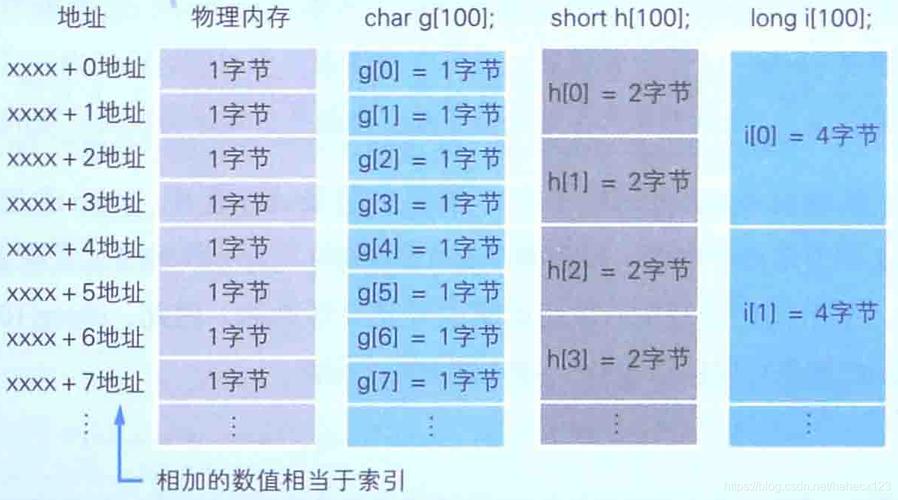
汉字编码简史
汉字的数字化存储始于20世纪中叶,随着计算机技术的发展,人们开始探索如何将汉字编码为机器可读的形式,最初的尝试包括使用图形方式存储,但这显然不是最有效的方法,随后出现了多种汉字编码标准,如GB2312、GBK、GB18030等,这些标准在不同的时期和地区被广泛采用。
Unicode与UTF8
随着全球化的发展,需要一个统一的字符集来支持全世界所有的文字系统,Unicode应运而生,Unicode为每个字符分配了一个唯一的代码点,而UTF8是Unicode的一种实现方式,它采用1至4个字节来表示一个字符,长度可变,对于汉字而言,大多数情况下,UTF8编码会使用3个字节来表示。
存储需求分析
常见汉字编码标准
| 编码标准 | 发布时间 | 覆盖范围 | 字节/汉字 |
| GB2312 | 1980年 | 简体中文 | 2 |
| GBK | 1995年 | 简体中文 | 2 |
| GB18030 | 2000年 | 全球字符 | 1~4 |
| Unicode | 1991年 | 全球字符 | 1~4 |
实际应用情况
在实际应用中,GBK编码因其较好的兼容性和较低的存储需求,在中国大陆地区得到了广泛应用,随着国际化的需求增长,UTF8逐渐成为主流,尤其是在互联网应用中。
技术细节
UTF8编码根据不同的字符采用不同长度的编码:
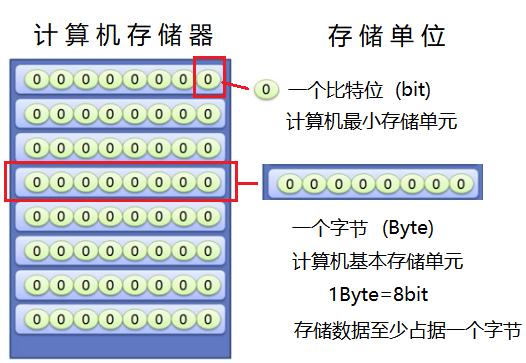
ASCII字符:1个字节
拉丁文等扩展ASCII字符:2个字节
汉字及emoji等字符:3个字节或更多
具体到汉字,UTF8编码通常会使用3个字节,第一个字节的前几位用于标识这是一个3字节的字符,后续两个字节则携带实际的字符信息。
归纳与建议
存储一个汉字所需的字节数取决于所采用的编码标准,在GBK等旧标准下通常需要2个字节,而在更为通用的UTF8编码下则需要3个字节,随着信息技术的发展和国际交流的增加,推荐使用UTF8编码,它不仅能兼容几乎所有的字符集,还能保证数据在全球范围内的一致性和互操作性。
选择正确的编码标准对于软件开发者来说至关重要,特别是在处理多语言文本数据时,开发者应确保应用程序能够正确处理不同编码标准下的字符,以避免乱码和数据丢失的问题,考虑到存储空间和网络带宽的限制,合理选择编码标准也有助于优化资源使用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/798938.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复