


快速排序是一种经典的排序算法,由Tony Hoare在1960年代提出,其基本思想是采用“分而治之”的策略,将大问题分解为小问题来解决,这种排序方法以其高效性而闻名,被广泛应用于各种编程场景中,下面将深入探讨快速排序的不同版本及其特性,特别是关注那些优化了排序规则的版本。
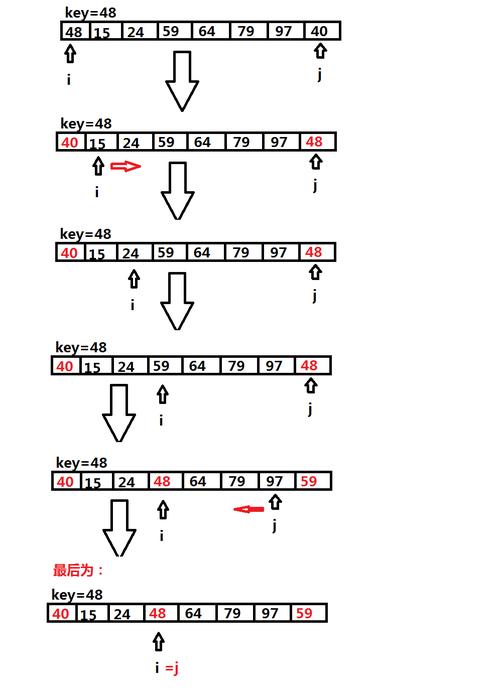

基本快速排序算法
快速排序的基本步骤可以分为三部分:选择基准值(pivot)、分区(partitioning)和递归排序子数组,首先选择一个元素作为基准值,然后将数组分为两部分,一部分包含所有小于基准值的元素,另一部分包含所有大于或等于基准值的元素,这个过程称为分区操作,对这两部分分别进行快速排序,直到整个数组变成有序状态。
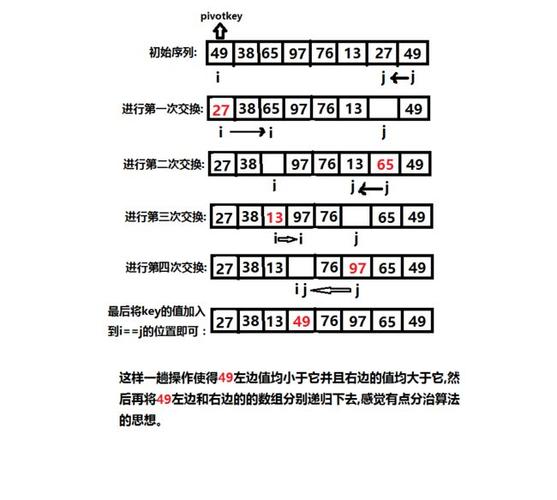
Hoare版本的快速排序
Hoare版本的快速排序在分区时有一个特点,即begin和end指针同时从数组的两端向中间移动,这种方法有助于减少数据移动的次数,尤其是在数组已经部分有序的情况下,能够提高排序效率,虽然该算法的平均时间复杂度为O(n log n),但在最坏情况下,如数组已经完全有序或逆序,性能会退化到O(n^2)。
三向切分的快速排序
对于包含大量重复元素的数组,一种改进的快速排序变体——三向切分的快速排序表现出更好的性能,这种方法将数组分为三部分:小于、等于和大于基准值的部分,通过这种方式,可以有效处理重复元素多的情况,提高排序的稳定性和效率。
标准库中的快速排序实现
在不同的编程语言标准库中,也可以找到快速排序的实现,C语言的qsort函数就是一种快速排序算法的实现,它定义在<stdlib.h>头文件中,这个函数利用了快速排序算法的平均时间复杂度为O(n log n)的优势,适用于各类数据的排序需求。
值得注意的是,在实际应用中,选择合适的快速排序版本需要考虑数据的特性(如数据的分布、重复元素的数量等),对于部分有序或者包含大量重复元素的数据集,选择Hoare版本或是三向切分版本的快速排序会更加高效。
快速排序作为一种高效的排序算法,通过不同的优化版本,可以适应各种不同的应用场景和数据类型,无论是在标准库中的广泛应用,还是针对特定数据类型的优化版本,快速排序都展现了其在排序算法中的重要地位,了解和选择正确的快速排序版本,可以显著提升程序的性能和效率。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/798758.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复