


YOLOv3是一种基于深度学习的物体检测模型,它通过使用单一的神经网络来同时预测物体的类别和位置,达到实时检测的效果,下面将详细探讨如何使用Darknet YOLOv3在AI市场进行物体检测:

1、环境配置
软件需求:为了运行YOLOv3,需要Python 3.7或更高版本,建议通过Anaconda进行环境配置。
库依赖:必须安装Numpy和OpenCV,这些库是处理图像和数学运算的基础。
GPU加速:如果希望利用GPU加速,确保你的系统已经安装了CUDA,并且需要修改Makefile中的设置以启用GPU支持。
2、安装Darknet
克隆仓库:从GitHub克隆Darknet仓库到本地。
编译项目:在darknet目录下执行make命令进行编译,若需GPU支持则要修改Makefile文件。

解决编译问题:对于遇到编译问题的,例如GCC版本不兼容,可通过创建软链接来使用特定版本的编译器。
3、模型训练与优化
选用模型权重:可以选择使用预训练的YOLOv3权重文件或者根据特定数据集进行模型训练。
数据集处理:根据实际应用场景对数据集进行扩充和优化,这可以提升模型的准确性和鲁棒性。
4、预处理输入图片
图片尺寸调整:输入的图片需调整为YOLOv3可以处理的尺寸,通常为多维度的正方形,如416×416。
归一化处理:对图片进行归一化,这是神经网络要求的标准化输入格式。

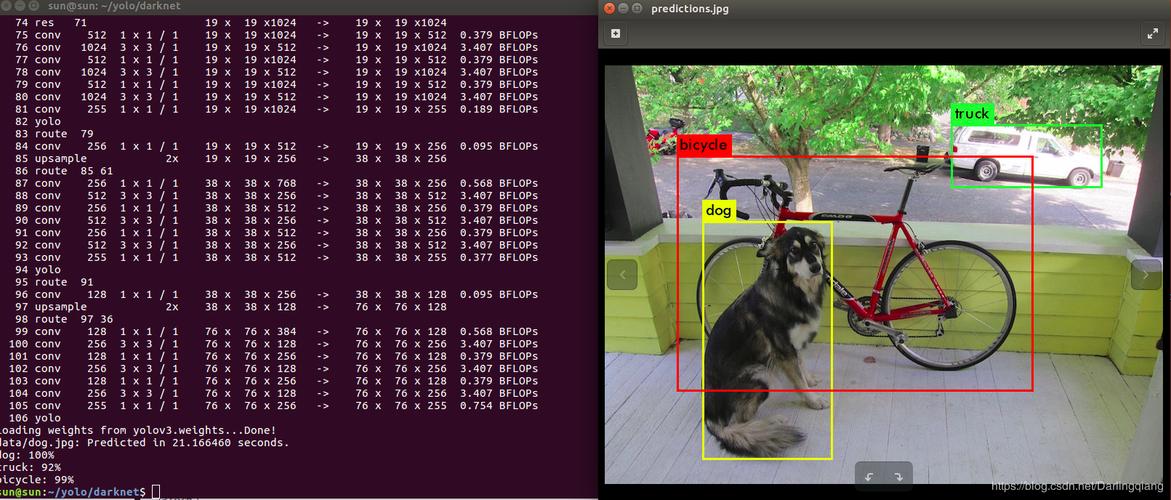
5、运行检测
摄像头读取:可以通过OpenCV调用摄像头捕获视频流并对其进行实时检测。
静态图片检测:也可以对静态图片进行检测,用于测试或离线分析。
6、结果处理与优化
还原预测框:将预测框(bounding box)还原至原图,以便可视化检测结果。
性能优化:针对检测效果和速度进行优化,可能涉及调整模型参数或使用不同的优化算法。
YOLOv3是一个功能强大且效率极高的物体检测模型,通过上述步骤可以有效地将其应用于AI市场的物体检测任务中,从环境配置到模型训练,再到实际的检测运行和结果优化,每一步都为最终的检测效果提供了保障。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/797252.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复