


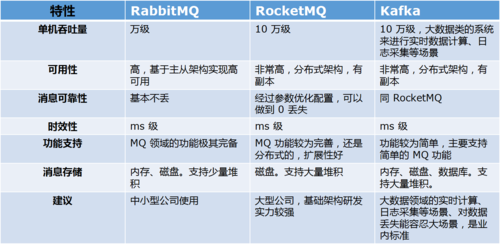
在探讨单线程取数据库与Kafka、RabbitMQ的差异之前,了解各自的基本工作原理和设计目标是很重要的,单线程取数据库通常涉及到直接从数据库中顺序读取数据,而Kafka和RabbitMQ则是分布式消息系统中的两个流行选项,它们主要用于处理消息的发送和接收,三者在消息处理模式、数据一致性以及容错性等方面有所区别,具体分析如下:

1、消息处理模式
单线程取数据库:在单线程模式下,数据库操作通常是同步的,逐个进行,这意味着消息的处理顺序是固定的,但处理速度可能较慢。
Kafka:设计为高吞吐量的分布式流处理平台,在同一主题同一分区内保证消息顺序,适用于处理大规模数据流。
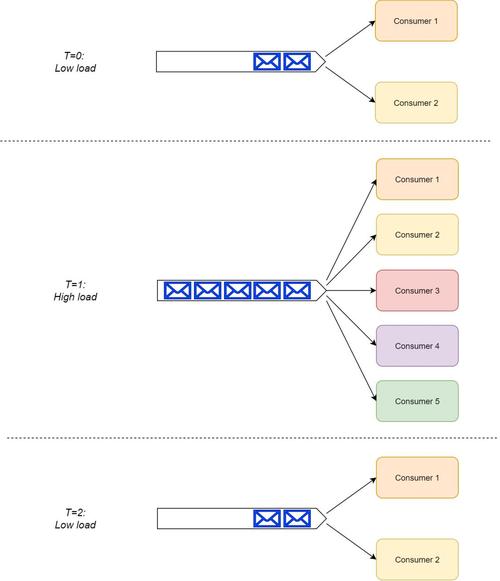
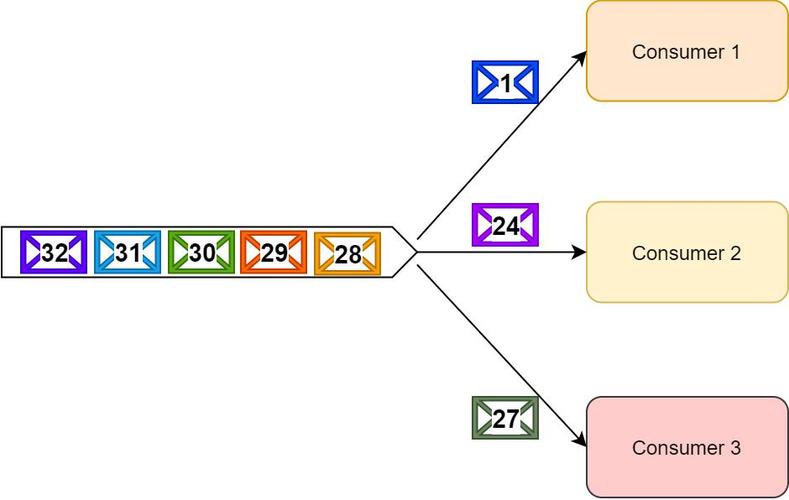
RabbitMQ:作为消息代理中间件,提供基本的消息顺序保证,若多线程消费时可能出现乱序现象,支持重试逻辑和死信交换。
2、数据一致性
单线程取数据库:严格的数据一致性,因为操作是同步执行的。
Kafka:虽然可以通过设置实现数据不丢失,但存在较小概率的数据重复发送情况。
RabbitMQ:在金融场景中经常使用,数据丢失的可能性更小,具有较高的严谨性。
3、容错性
单线程取数据库:容错性较低,一旦线程崩溃,整个处理过程停止。
Kafka:分布式设计,系统具备高容错性和可扩展性。
RabbitMQ:支持集群部署,提高了系统的容错能力。
4、延迟
单线程取数据库:延迟可能较高,尤其在数据量大时。
Kafka:低延迟处理大量消息,适合实时数据处理需求。
RabbitMQ:实时性较高,适用于需要近乎实时处理的场景。
5、吞吐量
单线程取数据库:吞吐量相对较低,受限于单线程性能。
Kafka:优秀的吞吐量,能处理高并发消息流。
RabbitMQ:虽吞吐量不如Kafka,但足够应对多数应用场景。
6、复杂性
单线程取数据库:实现简单,但难以处理复杂场景。
Kafka:分布式系统,配置和维护相对复杂。
RabbitMQ:提供了丰富的特性,如消息确认、死信队列等。
7、适用场景
单线程取数据库:适合简单的数据读取和处理。
Kafka:适合需要处理大量数据流和日志聚合等场景。
RabbitMQ:适合对数据一致性要求较高的交易处理。
8、异常处理
单线程取数据库:异常处理较为单一,容易中断整个流程。
Kafka:不保证每条消息只送达一次,可能会造成消息重复。
RabbitMQ:消费失败的消息会再入队,可能导致乱序,但支持重试和死信交换。
可以看出单线程取数据库、Kafka和RabbitMQ各有千秋,选择哪种方式取决于具体的应用需求和场景特点,对于需要高吞吐量和可扩展性的大规模数据流处理,Kafka可能是更好的选择;而对于需要高数据一致性和可靠性的交易处理系统,RabbitMQ则可能更适合。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/795247.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复