


Kettle,是一款广受欢迎的开源ETL(Extract, Transform, Load)工具,广泛用于数据抽取、转换、装入和加载,作为Pentaho Data Integration的一部分,Kettle对于处理海量数据和数据迁移拥有显著的优势,但面对现代的云数据库连接需求,用户可能对具体操作步骤并不十分清晰。

要了解如何运用Kettle连接云数据库并导入数据,需要遵循一系列具体的操作步骤,这些步骤涉及Kettle的基本使用方式、云数据库的配置和连接方法,下面将分点详细解释如何使用Kettle连接到云数据库,并利用其进行数据导入:
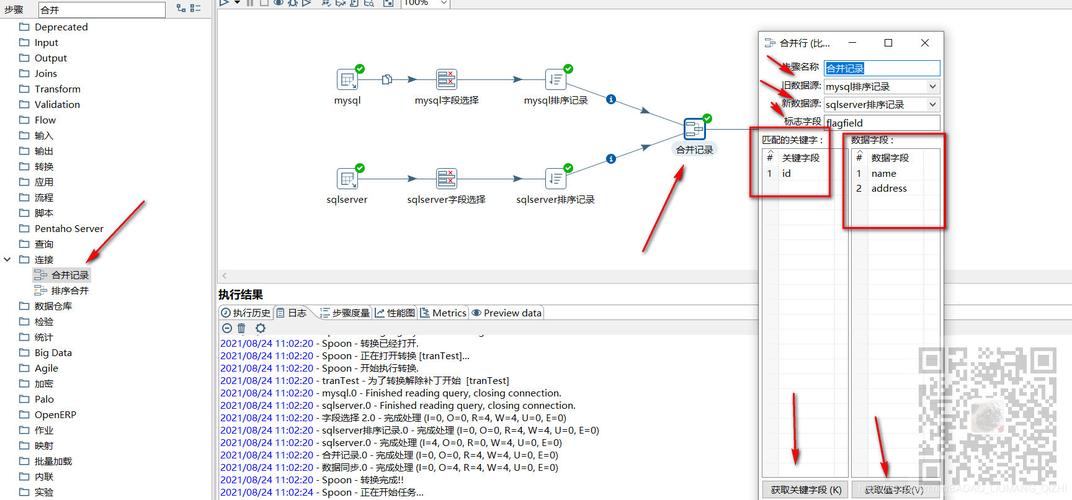
1、Kettle的基本使用
新建转换:在Kettle中,首先需要新建一个转换(Transformation),这可以通过文件菜单中的新建选项来完成,或者直接点击新建图标开始操作。
选择输入和输出:确定数据抽取的源头和目标,从MySQL数据库抽取数据,再加载到另一个数据库中,就需要分别设置输入和输出的数据源类型。
2、配置连接信息
自定义连接名称:在配置数据库连接时,需要自定义一个连接名称以便识别和管理。
配置数据库连接信息:配置数据库连接信息是关键一步,包括数据库的URL、用户名和密码等,这些信息确保Kettle能够正确连接到指定的云数据库。
3、连接云数据库
云数据库的特殊性:云数据库相比普通数据库,可能会有特定的连接方式和要求,例如通过jdbc连接URL进行访问。
不同云数据库的连接方式:阿里云RDS MySQL数据库等云数据库服务提供了详细的连接指南,可以根据提供商的文档完成相应设置。
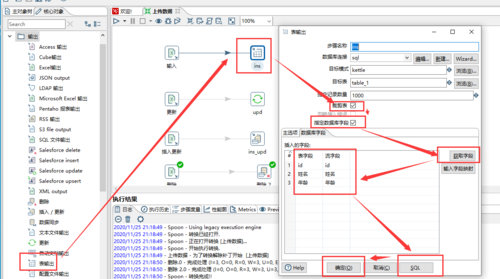
4、数据抽取和转换
数据抽取:使用Kettle的数据抽取功能,可以从源数据库中读取数据,为后续的转换和加载做准备。
数据转换:Kettle强大的数据转换功能可以对抽取的数据进行必要的清洗和加工处理,满足导入目标数据库的要求。
5、数据加载
加载到云数据库:经过转换后的数据,可以使用Kettle的数据加载功能写入到目标云数据库中。
性能考虑:在海量数据搬迁的场景下,入库速度是一个重要的考量因素,Kettle自身提供的数据入库插件可以实现高达1500条/秒的速度,但根据实际情况可能需要更高效的解决方案。
6、优化和问题解决
入库速度优化:针对数据导入的速度问题,可以考虑使用更加高效的插件或者调整Kettle的并行运行设置来提高性能。
云数据库连接问题:遇到连接问题时,应检查网络设置、数据库权限以及jdbc驱动是否正确无误。
在实施过程中,还有一些关键点需要特别注意:
确保Kettle的版本兼容目标云数据库;
验证网络连通性,以保障Kettle能够顺畅连接到云数据库;
提前在云数据库端设置好相应的权限和白名单,允许来自Kettle的连接请求;
根据实际的数据量和网络条件,选择合适的时间和方式进行数据迁移,避免影响业务系统的正常运行;
在正式迁移前,先进行小规模的测试运行,确认所有步骤都已经正确设置。
使用Kettle连接云数据库并导入数据是一项涉及多个步骤的操作,从新建转换、配置连接信息,到数据抽取、转换和加载,每一步都需要细致的规划和执行,在面对海量数据的迁移时,还需要关注性能优化和问题解决策略,遵循上述步骤和注意事项,用户可以高效、准确地完成数据迁移工作。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/794874.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复