

在当今互联网时代,网络数据呈现爆炸式增长,这些数据中蕴含着极大的信息价值,Java爬虫正是在这样的背景下,以其强大的网络编程能力成为了获取和处理网络数据的利器,下面将详细解析Java爬虫的基本概念、实现方式、应用场景以及优缺点等方面,以便全面理解Java爬虫的工作机制和应用价值。

1、Java爬虫的定义与原理
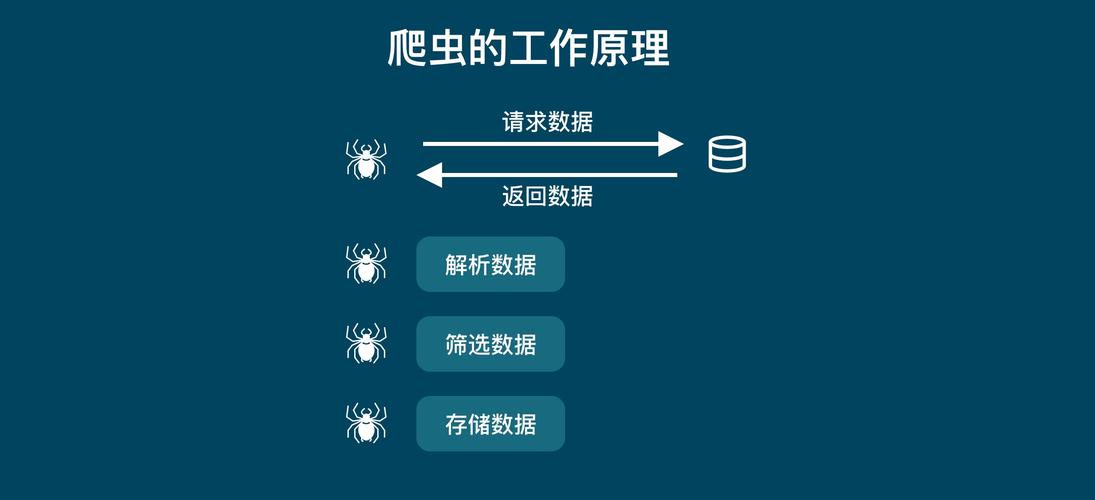
定义:Java爬虫,又称为网络蜘蛛,是一种模拟浏览器行为,按照预设规则自动抓取互联网信息的程序。
工作原理:它通过访问并解析网页,提取出所需的数据,这一过程包括发送HTTP请求、获取响应数据、解析这些数据并提取有价值的信息。
2、Java爬虫的实现技术
Jsoup库:Jsoup是一款非常流行的Java HTML解析器,它不仅能够提取和操作HTML元素,还可以用来执行HTTP请求,直接将远程HTML页面抓取到内存中进行分析和解析。

第三方框架:如Heritrix, crawler4j, WebMagic等不同的爬虫框架,提供了更为强大和灵活的网络爬取功能,可以大大简化爬虫程序的开发过程,这些框架各有千秋,开发者可以根据项目需求选择最适合的框架。
3、Java爬虫的应用领域
数据挖掘:从海量的网络数据中挖掘出有价值的信息,如市场分析、用户行为研究等。
竞品分析:抓取竞争对手的网站信息,比如产品价格、用户评价等,为企业决策提供数据支持。
内容聚合:自动从多个源收集新闻或文章,为内容平台提供新鲜的素材。
4、爬虫技术的优缺点
优点:自动化程度高,能够节省大量的人力成本;扩展性强,易于维护和升级;跨平台性能好,能够在多种操作系统上运行不受限制。
缺点:受网站结构变化影响大,一旦目标网站结构变动,可能需要重新配置爬虫规则;不当的爬虫行为可能会对网站造成压力,甚至触犯法律风险。
Java爬虫作为获取互联网信息的有效工具,其重要性不言而喻,掌握如何使用Java编程语言高效地编写和管理爬虫程序,对于希望从网络数据中提取有价值信息的开发者来说,是一项非常重要的技能,通过上述对Java爬虫的基本原理、实现方式、应用场景以及优缺点的详细解析,可以帮助读者全面而深入地理解Java爬虫的概念和实用价值,进而更好地利用这一技术在实际项目中发挥作用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/794473.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。