


快速原型模型在软件开发中常用于迅速构建一个可运行的模型,以验证概念和设计,而“快速添加日志告警模型”可能是指在现有系统或服务中快速实现日志记录和异常告警机制的过程,以下是关于如何实现这一过程的详细指南:

1. 确定需求和场景
在开始之前,需要明确哪些操作、事件或错误需要被记录和告警,可能需要对登录失败、支付异常、系统资源耗尽等情况发出告警。
2. 设计日志和告警架构
a. 日志记录策略
级别: 定义不同级别的日志,如INFO, WARN, ERROR, FATAL等。
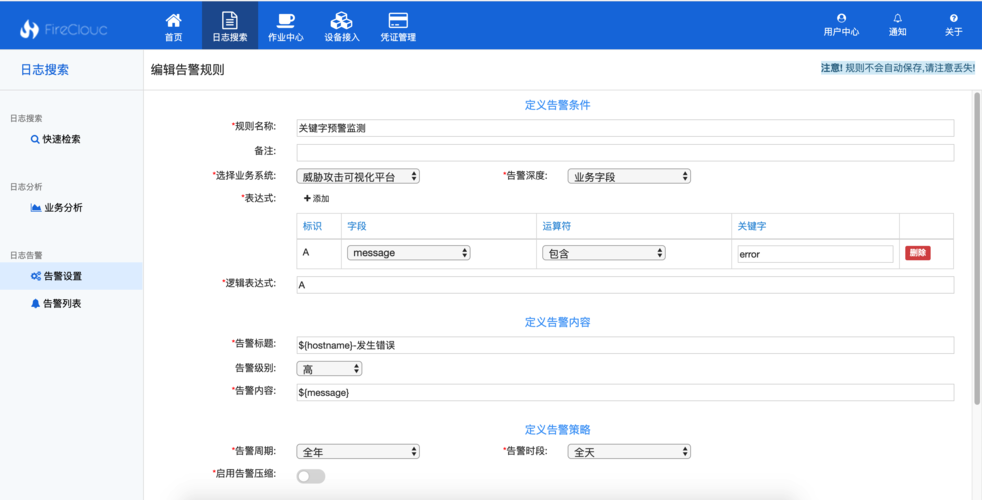
格式: 统一日志格式,包括时间戳、日志级别、源、消息ID、用户信息等。
存储: 选择日志存储位置,如本地文件、数据库或云日志服务。
b. 告警策略
阈值: 设置触发告警的阈值,例如连续5次登录失败。
渠道: 定义告警通知的渠道,如邮件、短信、电话或即时通讯工具。
接收者: 指定接收告警通知的人员或群组。
3. 选择合适的工具和技术
根据项目需求和团队技能,选择合适的日志库和告警系统。
日志库: Log4j (Java), Winston (Node.js), Logback (Python)等。
告警系统: Prometheus + Alertmanager, ELK Stack (Elasticsearch, Logstash, Kibana)等。
4. 实施日志记录
在代码中添加日志记录点,确保关键操作和异常被记录,在处理用户请求时:
try {
// 业务逻辑
} catch (Exception e) {
logger.error("处理用户请求时发生错误", e);
} 5. 配置告警规则
根据设计的告警策略,配置告警规则,以Prometheus为例:
groups:
name: example
rules:
alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency 6. 集成和测试
将日志和告警系统集成到项目中,并进行测试以确保它们按预期工作,测试应覆盖正常操作和异常情况。
7. 监控和维护
上线后,持续监控日志和告警系统的性能和准确性,定期回顾告警规则,确保它们仍然适用。
8. 文档和培训
编写详细的文档,说明日志和告警系统的工作原理、配置方法和响应流程,对团队成员进行培训,确保他们知道如何处理告警。
9. 反馈和迭代
收集使用过程中的反馈,并根据反馈不断优化日志和告警系统,这可能包括调整日志级别、添加新的告警规则或改进通知渠道。
通过以上步骤,可以快速地为现有系统添加日志记录和告警功能,提高系统的可维护性和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/794401.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复