


揭秘Java爬虫:互联网数据抓取与处理的利器

网络爬虫,这一在信息时代至关重要的技术,已经成为获取、分析和管理海量网络信息的关键工具,Java爬虫,特别地,利用Java语言的强大功能和广泛应用,为自动化抓取网络数据提供了强有力的支持,在互联网技术迅猛发展的今天,掌握Java爬虫技术意味着能够在数据的海洋中更自由地航行。
网络爬虫,亦或是网络蜘蛛、网络蚂蚁等,其本质是一种自动浏览网络信息的程序,它按照预设的规则——网络爬虫算法,系统地筛选和收集网络中的所需信息,这类程序因任务的不同而呈现出多样化的形态,既可以是通用搜索引擎中用于索引网络内容的百度蜘蛛,也可以是专为特定数据采集设计的定制爬虫。
Java爬虫的作用不仅仅是数据抓取那么简单,与其他语言编写的爬虫相比,Java爬虫在处理大型、复杂的数据采集任务时显得尤为得心应手,Java语言本身的健壮性、跨平台特性以及丰富的库支持,使得用Java编写的爬虫在可靠性、易维护性及扩展性方面拥有显著优势。
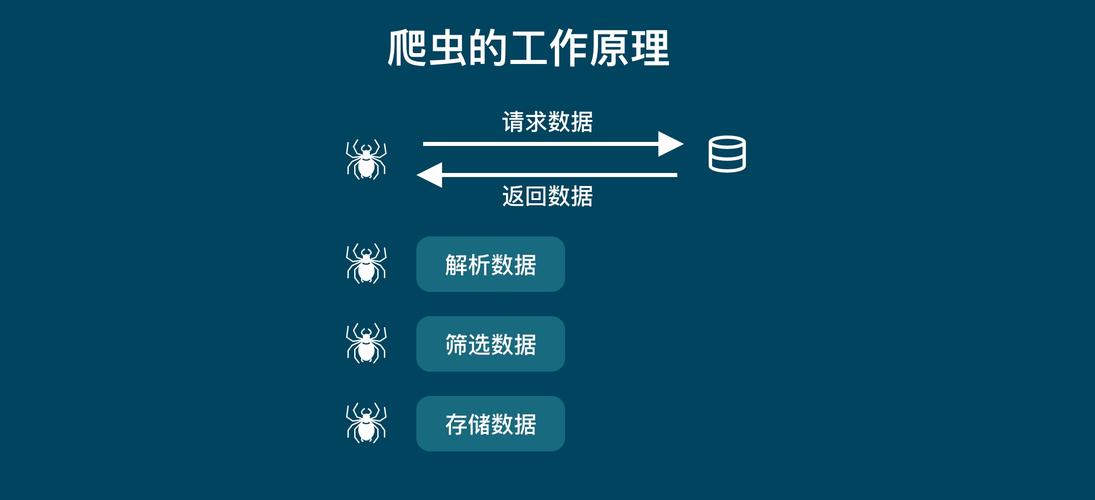
Java爬虫的工作原理可以大致分为三个步骤:它通过发送网络请求来访问目标网页;然后对网页内容进行解析,通常涉及HTML解析;最后将解析得到的数据存储起来供后续使用,在这个过程中,可能会融入各种高级技术,如分布式爬取(利用Hadoop等工具),以提升爬虫的效率和处理能力。
在实际应用中,Java爬虫能够执行多种任务,它可以帮助搜索引擎优化其数据库,就像百度蜘蛛那样,不断爬取新的内容并更新索引,Java爬虫也被广泛用于网站内容管理,比如检查链接有效性、收集竞争对手的信息等。

值得一提的是,WebCollector是一个易于二次开发的Java爬虫框架,它通过简化的API让开发者只需编写少量代码就能实现一个全功能的爬虫,WebCollectorHadoop版本更是支持了分布式爬取,大大提升了处理大规模任务的能力。
对于希望深入学习Java爬虫的人来说,视频教程是一个非常有用的资源,系统化的讲解结合实例代码,能够帮助学习者更好地理解爬虫的工作原理并掌握其开发技巧。
在这个信息化快速发展的时代,Java爬虫技术无疑是一种重要的技能,无论是数据分析、网络监控还是智能决策支持,Java爬虫都能发挥出其强大的作用,掌握Java爬虫,意味着掌握了一种全新的信息获取方式,这将为研究和开发工作带来巨大的便利。
随着技术的不断进步和应用的深入,Java爬虫的潜力正被逐步挖掘,从学术研究到商业应用,从个人项目到企业解决方案,Java爬虫正在成为越来越多领域不可或缺的重要工具。
在这个信息爆炸的时代,Java爬虫作为一种高效的数据抓取与处理技术,其价值和意义不言而喻,无论是对于开发人员、数据分析师还是互联网从业者,掌握并善用Java爬虫技术,都将成为获取信息、分析趋势、优化决策的强大助力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/792695.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复