


在当今的互联网时代,网页数据的抓取和分析成为了不可或缺的技能之一,Java爬虫技术以其强大的功能和灵活性,在数据抓取领域占据着举足轻重的地位,下面将深入探讨Java爬虫的技术细节及其应用:

1、Java爬虫的基础理论
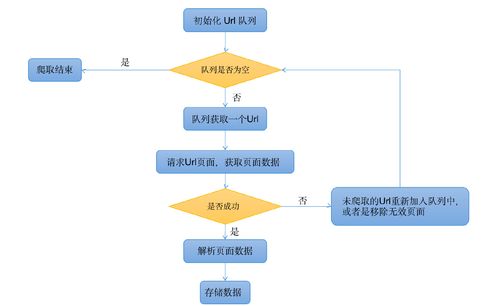
概念理解:网络爬虫是一种自动获取网页内容的程序,它按照预设的规则,自动遍历网页,收集信息并进行处理。
工作原理:爬虫通常通过模拟HTTP请求来访问网页,解析HTML代码,然后提取需要的数据,这一过程循环进行,以遍历多个页面。
2、Java爬虫的技术框架
Jsoup:Jsoup是一个用于处理HTML的Java库,它提供了非常方便的API来提取和操作数据,在Spring Boot项目中,可以通过添加Jsoup依赖来实现爬虫功能。
HttpClient:HttpClient是Apache的一个模块,它可以提供高效的HTTP请求功能,支持所有HTTP方法,是进行爬虫开发的强大工具。
WebMagic:WebMagic是一个开源的Java垂直爬虫框架,它提供了丰富的功能,如下载器、处理器等,使得定制化爬虫更加方便。
spiderflow:spiderflow是一个基于流式处理的爬虫框架,它允许用户通过配置而非编码的方式来实现爬虫逻辑,降低了开发难度。
3、Java爬虫的实现步骤
添加依赖:在项目的pom.xml文件中添加所需的爬虫库,如Jsoup。
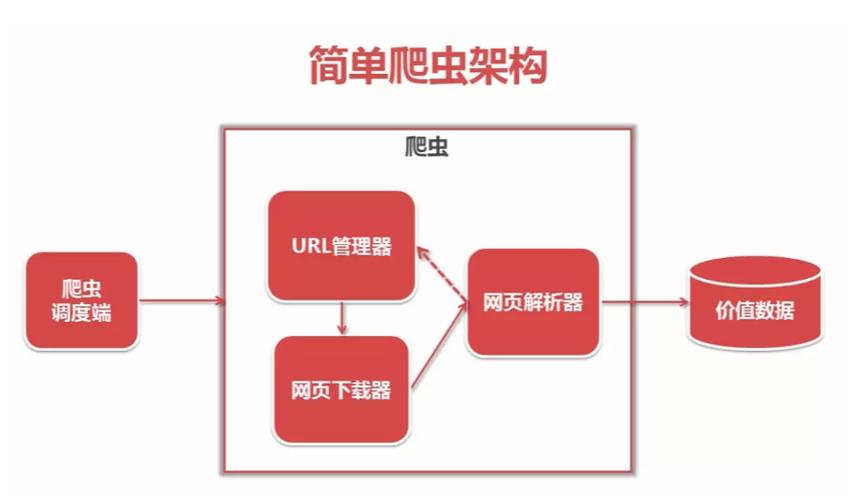
创建请求:使用HttpRequest等类创建一个HTTP请求,指定URL和请求方法。
解析响应:发送请求后,接收HTTP响应,使用Jsoup等解析库来解析HTML文档。
数据提取:从解析后的文档中提取需要的信息,如文本、图片链接等。
数据存储:将提取的数据保存到文件或数据库中,以便后续处理和分析。
4、Java爬虫的高级技巧
异步抓取:使用多线程或异步框架来提高抓取效率,减少等待时间。
动态渲染页面抓取:对于使用JavaScript动态生成内容的网页,可以使用如Selenium这样的工具来加载完整页面后再进行抓取。
反爬虫机制应对:网站可能通过IP检测、请求频率限制等方式反爬,爬虫需要采取更换IP、设置请求间隔等策略来应对。
5、Java爬虫的应用场景
数据分析:抓取网页数据进行分析,如市场调研、竞争对手分析等。
内容采集:自动采集新闻、博客等内容,为内容聚合平台提供数据源。
监控报告:实时监控网站上的信息变化,如价格变动、新闻更新等,并生成报告。
6、Java爬虫的发展趋势
智能化:随着人工智能技术的发展,爬虫技术将更加智能化,能够更好地识别和处理各种类型的网页。
自动化:爬虫的自动化程度将进一步提高,减少人工干预,提高效率。
法律合规性:随着法律法规的完善,爬虫的合法使用将成为开发者必须考虑的问题。
7、Java爬虫的注意事项
遵守协议:尊重网站的robots.txt文件,不抓取禁止抓取的内容。
避免滥用:合理控制抓取频率,避免对网站造成过大压力。
隐私保护:在抓取和处理个人数据时,要遵守相关的隐私保护法规。
8、Java爬虫的学习资源
在线教程:通过网络上的免费或付费视频教程学习爬虫的基础知识和进阶技巧。
书籍推荐:《Java网络编程》等书籍可以提供系统的学习材料。
社区交流:参与开源社区和论坛,与其他开发者交流经验和问题。
Java爬虫作为一种高效的网页数据抓取工具,其技术和应用在不断进步和发展,掌握Java爬虫技术不仅能够帮助人们从海量的网络数据中提取有价值的信息,还能够推动数据驱动的决策制定,技术的使用也应遵循法律法规和道德规范,确保数据抓取的合法性和合理性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/792675.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复