


在创建大数据模型时,数据建模是指将业务问题转换为数据形式的过程,以便通过数据分析来解决这些问题,大数据建模不仅要处理来自不同来源和形式的庞大数据集,还要确保模型的开放性和弹性,以适应数据的快速增长和变化,具体分析如下:


01、选择基座模型
有效性与成本:选择适合的基座模型是关键步骤,需要平衡模型的效果和部署成本,ChatGLM36B模型尽管参数量相对较少,但在效果上却十分突出,为低成本部署提供了可能。
微调与优化:通过有监督微调可以使得基座模型更好地适应特定应用场景,从而在特定任务上实现更优的性能。
02、传统与大数据建模方法
传统数据分析建模方法:这种方法依赖于关系数据库模式,侧重于数据之间的关系和链接,适用于数据增长稳定可预测的场景。
大数据建模方法:与传统方法不同,大数据分析方法应对的是指数增长和多种形式的数据,这要求建模工作更加集中在构建一个开放和弹性的系统上。
03、数据建模的步骤
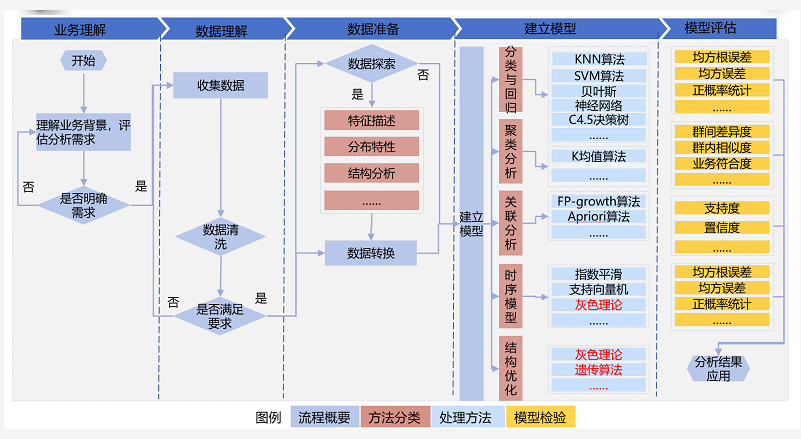
选择模型或自定义模式:根据业务需求选择合适的模型或者自定义模式,这要求对业务问题有深刻的理解以及相应的数据处理技能。
系统设计:设计一个能够适应各种数据源的系统,而不是单纯依赖数据库模式,这对于处理大数据尤其重要。
04、大数据建模的提示
避免传统技术的强加:传统的建模技术不适合直接应用于大数据环境中,需要更多关注数据的开放性和弹性接口的设计。
集中于系统设计:相对于建立固定的数据模式,大数据模型更应注重整体系统的设计,以适应快速变化的数据环境和需求。
05、数据源的多样化
接受数据多样性:大数据环境下,数据的多样性是常态,模型需能处理结构化、半结构化和非结构化的数据,增加模型的复杂性与挑战。

接口的灵活性:设计数据接口时,要考虑到未来可能出现的新数据源和形式,确保系统的扩展性与灵活性。
06、性能与效率的权衡
参数规模与计算资源:模型的大小和参数数量直接影响所需的计算资源,在不牺牲性能的前提下,选择合适规模的模型是优化资源使用的关键。
实时性与准确性:对于某些应用,模型需要实现接近实时的数据处理和响应,在保证准确性的同时提高模型处理速度,是一大挑战。
07、模型的验证与测试
结果校验:任何模型都需要经过严格的验证和测试,以确保其输出符合预期,特别是在处理大规模数据时,这一点尤为重要。
持续迭代:基于反馈和实际使用情况,不断调整和优化模型,是保持模型有效与适应性的必要过程。
大数据模型创建是一个涉及多方面考虑的复杂过程,从选择基座模型到设计系统,再到模型的验证和测试,每一步都需要精心设计和执行,通过遵循上述步骤和提示,可以有效地构建出既适应当前需求又具备未来扩展性的大数据模型,从而最大化地发挥大数据的价值,支持复杂的数据分析和决策制定。
相关问答FAQs
Q1: 如何选择合适的基座模型?
A1: 选择合适的基座模型主要依据模型的效果和部署成本,参考开源评测平台如OpenCompass提供的数据进行选择,清华大学发布的ChatGLM36B模型因其优异的综合性能和较低的参数量成为优选。
Q2: 在大数据建模中,为何强调系统设计而非数据库模式?
A2: 由于大数据的多样性和不可预测性,传统的数据库模式难以适应快速变化的数据源和形式,大数据模型应更注重系统的整体设计,确保模型具有足够的开放性和弹性,以适应不断变化的数据环境。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/791194.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复