


Kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于Zookeeper协调的分布式消息系统,最初由LinkedIn公司开发,并于2010年贡献给了Apache基金会成为顶级开源项目,作为一个高吞吐量的发布订阅消息系统,Kafka被设计用于处理大规模实时数据流,广泛应用于多种数据处理场景,如日志收集、实时数据分析等,下面将从多个维度详细分析Kafka的核心特性及其在实际应用中的表现:
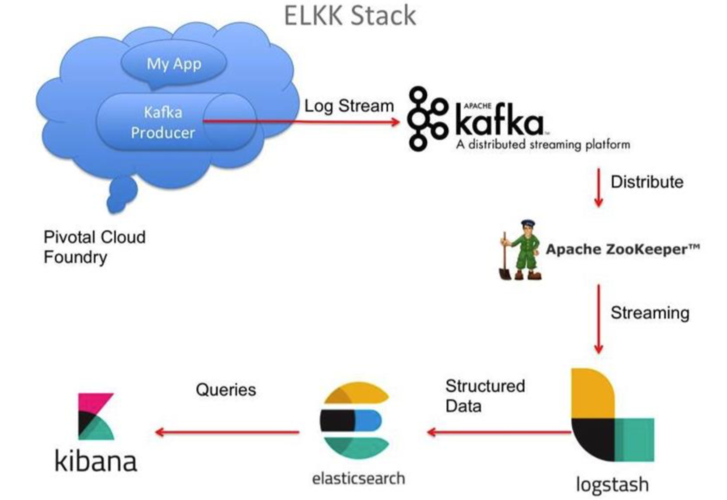

1、基本架构和组件
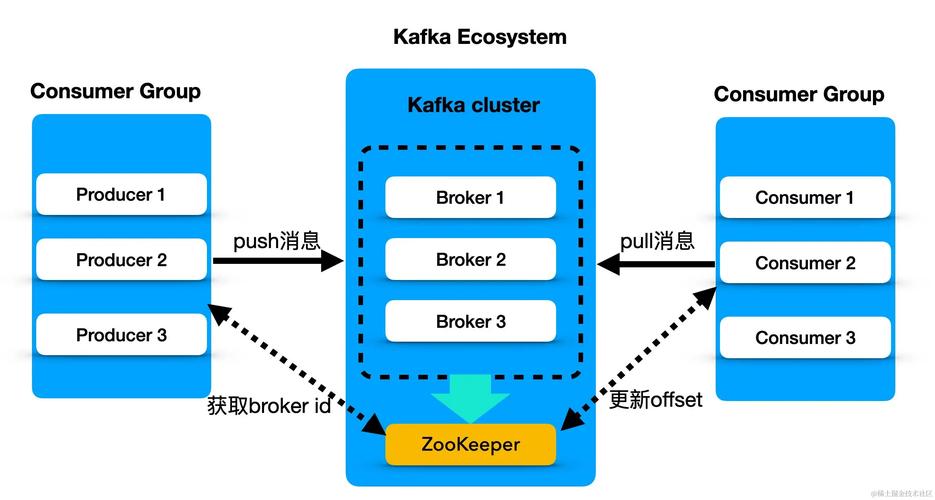
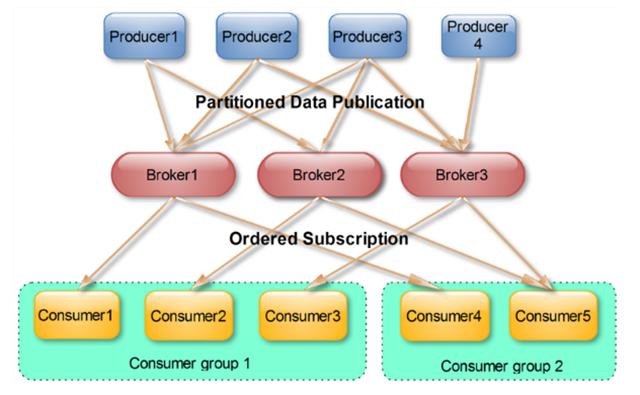
Producer:生产者,发送消息到Kafka集群。
Broker:Kafka的服务节点,负责接收和存储消息。
Consumer:消费者,从Kafka集群拉取并消费消息。
Topic:消息类别,生产者发送到Topic,消费者从Topic读取。
Partition:每个Topic分为多个Partition,实现并行处理。
Replica:每个Partition可有一个或多个副本,确保数据高可用。
Zookeeper:管理Broker集群,实现负载均衡和故障转移。
2、核心特性与技术优势
高吞吐量:通过批处理和对消息的I/O优化,实现高吞吐量。
可扩展性:通过增加Broker数量,轻松实现水平扩展。
持久性保证:通过多副本机制,保证消息的可靠性存储。
容错性:Zookeeper管理下,自动实现故障恢复和重新平衡。
3、文件存储机制
顺序写入:采用顺序写磁盘的方式,提高I/O效率。
零拷贝技术:减少数据复制操作,降低网络传输延迟。
页缓存利用:充分利用操作系统的页缓存,提升读写性能。
4、应用场景与实例
日志收集:高效地收集和汇总大量服务器日志数据。
实时分析:对接流式处理引擎如Storm/Spark,进行实时数据分析。
消息队列服务:作为解耦的消息队列,提高系统的伸缩性和灵活性。
5、设计与部署考量
Broker配置:合理规划Broker数量和硬件资源,满足性能需求。
Topic和Partition策略:根据业务量和并发需求,合理设置Topic和Partition数量。
副本和容错机制:根据数据重要性和容灾需求,配置合适的副本数目。
Kafka作为一个高效的分布式消息系统,其设计初衷就是为了满足现代大数据处理的复杂需求,通过其独特的分布式架构和存储机制,Kafka能够提供高吞吐量、低延迟的消息传递服务,同时保持系统的高可用性和可扩展性,在实际应用中,无论是作为日志收集平台,还是实时数据处理的解决方案,Kafka都能发挥巨大的作用,帮助构建稳健、高效的数据处理管道。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/791119.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复