

多任务学习(MultiTask Learning, MTL)是一种在机器学习领域广泛应用的技术,它允许模型同时学习多个相关任务,通过共享不同任务之间的表示或参数,MTL可以提高模型的泛化能力、数据利用效率以及减少过拟合的可能性,本文将详细介绍如何设置多任务学习中的处理模式,并探讨其优势和应用场景。


MultiStatements处理模式的设置
在多任务学习中,处理模式指的是模型如何处理多个任务的学习过程,通常有以下几种处理模式:
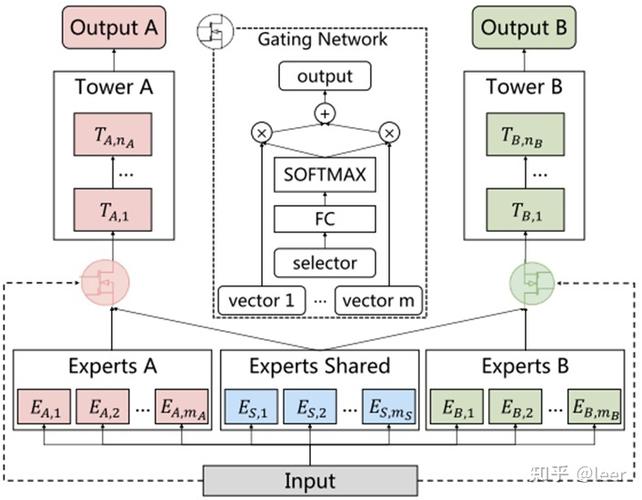
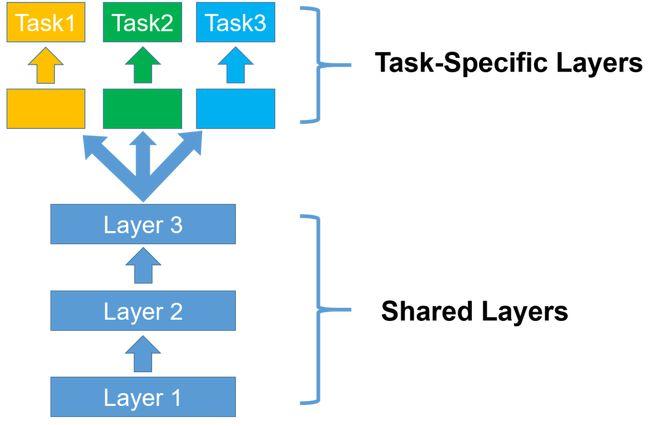
1、硬参数共享:在这种模式下,所有任务共享相同的网络底层,而顶层则针对不同的任务设计不同的输出层,这种模式适合任务之间相关性较强的情况。
2、软参数共享:每个任务有独立的模型结构,但在训练过程中会鼓励不同任务的参数接近,这可以通过正则化实现,比如使用参数的距离作为正则项。
3、分层参数共享:结合了上述两种模式的特点,底层参数被所有任务共享,而高层参数则根据任务的不同有所区分。
4、自定义架构:根据特定任务的需求,设计独特的模型架构,可能是上述模式的混合或者完全不同的新结构。
设置步骤
以下是设置多任务学习处理模式的具体步骤:
1、确定任务:首先明确要解决的任务,并评估它们之间的相关性。
2、选择模型架构:基于任务的相关性选择合适的模型架构,对于高度相关的任务,硬参数共享可能更合适;对于相关性较低的任务,可以考虑软参数共享或分层参数共享。
3、设计损失函数:设计一个综合的损失函数,能够平衡各个任务的学习需求。
4、调整超参数:包括学习率、正则化系数等,这些超参数需要根据具体的任务和模型来调整。
5、实施训练策略:决定是顺序训练还是联合训练,以及是否需要特定的训练技巧如梯度反转层(Gradient Reverse Layer)。
6、评估与优化:在验证集上评估模型性能,并根据评估结果进行必要的调整和优化。
优势与应用场景
多任务学习的优势在于:
提升模型泛化能力:通过多任务学习,模型可以在多个任务上获得更好的泛化性能。
提高数据利用效率:在数据量有限的情况下,多任务学习可以更有效地利用数据。
减少过拟合:多任务学习通过在多个任务上共享信息,有助于防止模型对单一任务的过拟合。
应用场景包括但不限于:
自然语言处理:在一个模型中同时处理词性标注、命名实体识别等多个NLP任务。
计算机视觉:同时进行物体检测和图像分类。
推荐系统:同时预测用户的点击率和转化率等。
相关问答FAQs
Q1: 多任务学习是否总是比单任务学习更好?
A1: 并不是,多任务学习的效果取决于任务之间的相关性,如果任务之间相互独立或负相关,多任务学习可能不会带来性能的提升,甚至可能导致某些任务的性能下降,在应用多任务学习之前,应该仔细分析任务之间的关系。
Q2: 如何在多任务学习中处理不均衡的数据?
A2: 在多任务学习中处理不均衡数据的策略与单任务学习类似,可以采用重采样、调整类别权重或使用合成数据等方法,还可以通过调整损失函数中的权重来平衡不同任务的学习难度,确保模型对少数类给予足够的关注。
通过合理设置处理模式和遵循上述步骤,可以有效地实施多任务学习,从而在多个任务上取得更好的性能,需要注意的是,多任务学习并非银弹,其效果受到任务相关性、数据质量和模型设计的多重影响。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/789197.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复