


在当今大数据时代,分布式计算已经成为处理海量数据集的标配技术,尤其是MapReduce模型,它通过将计算任务分发到多个处理节点上,并行处理数据,有效提高了处理速度,当涉及到多个MapReduce任务串联以及在多个NameService环境下运行时,任务执行失败的情况便时有发生,面对这样的挑战,理解其原因并找到合适的解决方案显得尤为重要,具体分析如下:

1、多MapReduce任务串联的挑战
任务依赖性:在进行多个MapReduce任务串联时,通常涉及到任务间的依赖,一个任务的输出可能是另一个任务的输入,这就要求系统能够准确控制任务的执行顺序,确保前序任务完成后才能启动后续任务。
数据一致性:串联的MapReduce任务需要保证数据的一致性,若前一个任务的输出数据在传输或存储过程中出现错误,可能导致后续任务执行错误或失败。
资源管理:每个MapReduce任务都需要消耗一定的系统资源,如内存、CPU等,在多任务串联的情况下,资源的分配与管理尤为关键,否则容易造成资源争用,影响任务的顺利进行。
2、多NameService环境的特殊挑战
权限与访问控制:不同的NameService环境可能有不同的权限设置和访问控制策略,这可能导致某些任务无法正常访问所需的数据或资源,尤其是在使用viewFS等特殊功能时更为明显。
配置复杂性:多NameService环境意味着更复杂的系统配置,对于MapReduce任务而言,如何正确配置以适应不同环境的NameService,是成功运行任务的前提之一。
环境隔离:在一些严格的多NameService环境中,为了数据安全和系统稳定性的考虑,可能会对计算任务进行逻辑或物理上的隔离,这增加了任务串联的复杂度。
3、故障原因及解决策略
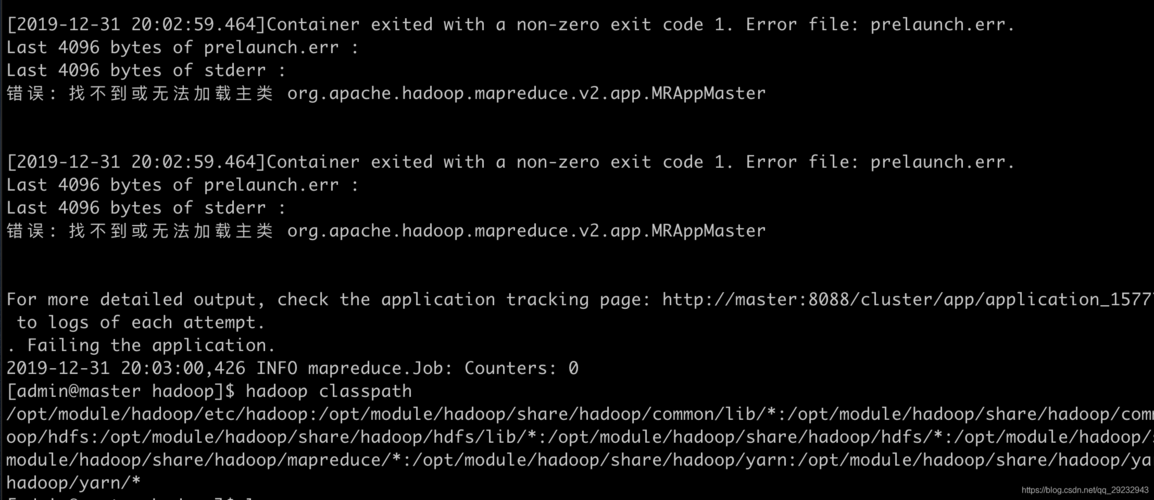
路径配置问题:如前所述,使用viewFS时,只有配置在viewFS挂载点上的路径才能被访问,确保所有任务的输入输出路径正确配置在viewFS的挂载点上,是避免任务失败的一个重要措施。
JobControl应用:为了管理多任务串联的依赖关系和执行顺序,可以使用MapReduce框架提供的JobControl工具,通过JobControl,可以方便地设置任务的依赖关系,确保任务按照预定的顺序执行。
资源调优与监控:合理分配和调度系统资源对于多任务串联的成功至关重要,可以通过YARN(Yet Another Resource Negotiator)来进行资源的统一管理和调度,同时监控系统资源的使用情况,避免资源成为任务失败的瓶颈。
在了解以上内容后,以下还有几点需要注意:
容错机制:设计合理的容错机制,如任务重试策略,可以有效应对偶发的任务失败问题。
解决数据倾斜问题,保持数据的均衡分布,避免某个节点因数据量过大而崩溃。
多个MapReduce任务串联以及在多个NameService环境下运行面临诸多挑战,但通过合理的配置、有效的资源管理以及严密的错误处理,大多数问题是可以被解决的,理解每个环节的具体需求和可能出现的问题,采取针对性的策略,是确保MapReduce任务顺利执行的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/788660.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复