

倒排索引(Inverted Index)是一种用于快速文本搜索的数据结构,广泛应用于搜索引擎和信息检索系统中,在Python中,我们可以使用字典(Dictionary)来实现一个简单的倒排索引。


倒排索引原理
倒排索引的主要思想是将文档内容分解成单词,然后为每个单词建立一个索引,记录包含该单词的文档ID,这样,在搜索时,我们只需要查找包含查询关键词的索引,而不需要遍历整个文档库。
Python实现倒排索引
以下是一个简单的Python代码示例,演示如何创建一个倒排索引:
假设我们有以下文档库
documents = [
"这是第一个文档",
"这是第二个文档",
"这是第三个文档",
"这是第四个文档",
]
创建一个空字典用于存储倒排索引
inverted_index = {}
遍历文档库,为每个单词建立索引
for doc_id, document in enumerate(documents):
words = set(document.split())
for word in words:
if word not in inverted_index:
inverted_index[word] = {doc_id}
else:
inverted_index[word].add(doc_id)
输出倒排索引
print(inverted_index) 运行上述代码,我们将得到一个如下所示的倒排索引:
{
'第一': {0},
'个': {0},
'二': {1},
'三': {2},
'四': {3},
'文档': {0, 1, 2, 3},
'是': {0, 1, 2, 3},
'这': {0, 1, 2, 3},
} 从这个倒排索引中,我们可以看到每个单词对应的文档ID集合,单词“文档”出现在所有四个文档中,因此其对应的文档ID集合为{0, 1, 2, 3}。
倒排索引的优势

1、快速搜索:由于倒排索引直接将单词映射到包含它的文档,因此在搜索时可以快速找到相关文档。
2、节省存储空间:与正向索引相比,倒排索引通常占用较少的存储空间,因为它只存储了单词和文档ID,而不是整个文档内容。
3、易于更新和维护:当添加或删除文档时,可以轻松地更新倒排索引。
倒排索引的局限性
1、构建成本:构建倒排索引需要一定的计算资源和时间,特别是对于大型文档库。
2、词汇表膨胀:随着文档库的增长,倒排索引的大小也会随之增加,可能导致内存不足的问题。
3、不支持复杂查询:基本的倒排索引结构不支持复杂的查询操作,如短语搜索、近似搜索等。
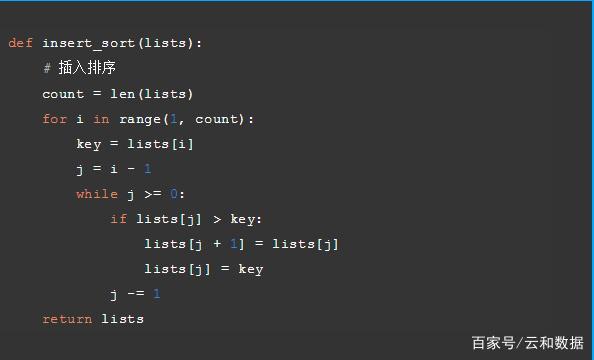
相关问答FAQs
Q1: 如何在Python中实现多字段倒排索引?
A1: 要实现多字段倒排索引,我们可以为每个字段创建一个单独的倒排索引,然后在搜索时合并这些索引的结果,以下是一个示例代码:
假设我们有以下文档库,每个文档包含标题和正文两个字段
documents = [
{"title": "第一个文档的标题", "content": "这是第一个文档"},
{"title": "第二个文档的标题", "content": "这是第二个文档"},
{"title": "第三个文档的标题", "content": "这是第三个文档"},
{"title": "第四个文档的标题", "content": "这是第四个文档"},
]
创建两个空字典用于存储标题和正文的倒排索引
inverted_index_title = {}
inverted_index_content = {}
遍历文档库,为每个字段的每个单词建立索引
for doc_id, document in enumerate(documents):
words_title = set(document["title"].split())
words_content = set(document["content"].split())
for word in words_title:
if word not in inverted_index_title:
inverted_index_title[word] = {doc_id}
else:
inverted_index_title[word].add(doc_id)
for word in words_content:
if word not in inverted_index_content:
inverted_index_content[word] = {doc_id}
else:
inverted_index_content[word].add(doc_id)
输出倒排索引
print("标题倒排索引:", inverted_index_title)
print("正文倒排索引:", inverted_index_content) Q2: 如何优化倒排索引的性能?
A2: 优化倒排索引的性能可以从以下几个方面进行:
1、压缩存储:对倒排索引进行压缩,以减少存储空间和提高加载速度,可以使用各种压缩算法,如BWT(BurrowsWheeler Transform)等。
2、缓存机制:使用缓存机制来存储最近访问的倒排索引数据,以减少磁盘I/O操作。
3、并行处理:利用多核处理器的并行计算能力,将倒排索引的构建和搜索任务分布到多个线程或进程上执行。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/787431.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复