


在电商平台上,商品评论对于消费者购买决策具有重要影响,维护一个健康、真实的评论环境对于商家及平台至关重要,以下将详细介绍电商评论内容过滤系统的更新评论过程:

1、数据爬取和导入
爬虫获取数据:使用Python等编程语言,通过编写网络爬虫自动收集电商平台上的评论数据,这一步骤是基础,也是整个过滤系统的数据来源。
导入预处理:将爬取到的数据利用数据处理库,如pandas进行导入和预处理,为后续分析做好准备。
2、文本数据处理
数据清洗:去除无关信息,如html标签、特殊符号等,确保文本数据的清洁性。
中文分词与去停用词:对中文文本进行分词处理,并去除一些无实际意义的停用词,以减少噪声数据对分析结果的影响。
词频统计:统计词频,识别出评论中出现频率较高的关键词,这有助于理解消费者的关注点。
3、情感分析与观点挖掘
LDA算法分析:利用LDA(Latent Dirichlet Allocation)算法从评论文本中发现隐藏的话题,探索消费者的主要评价和观点。
情感倾向判定:基于情感词典或机器学习方法,判断每条评论的情感倾向,如正面、负面或中性。
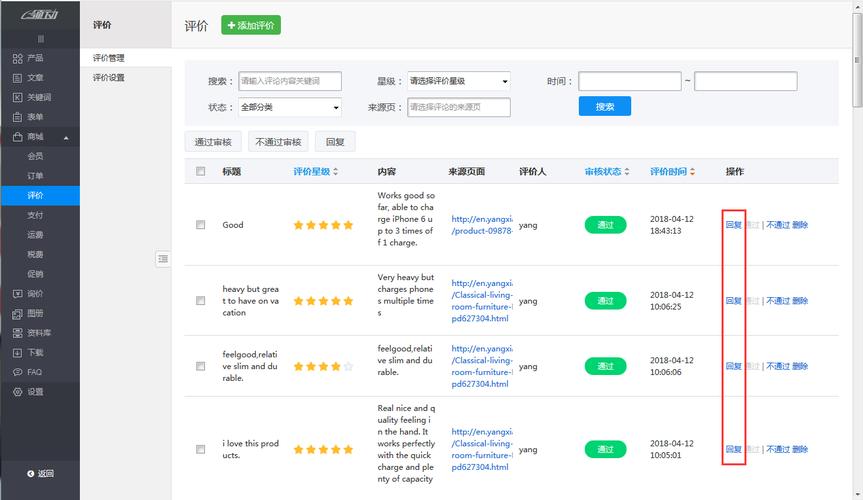
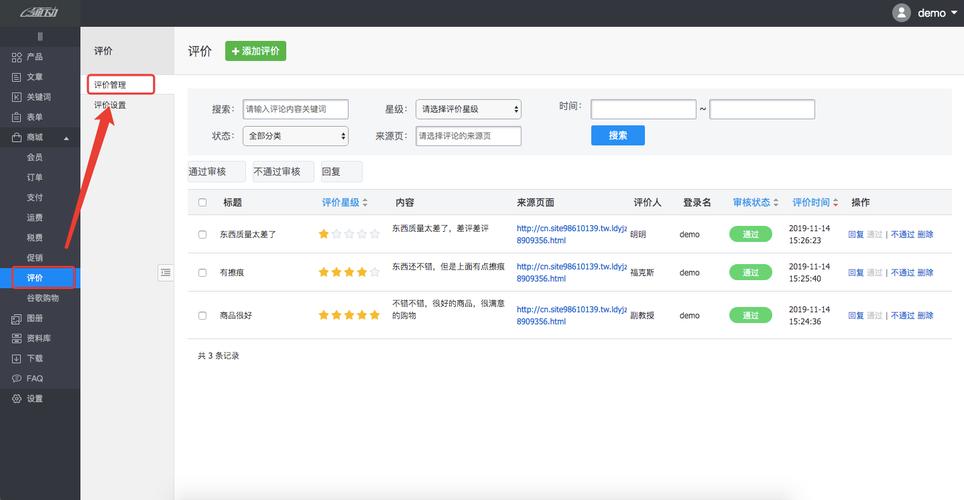
4、评论管理功能
评论列表展示:在管理页面上展示所有用户评论的列表,包括总评论数、机器过滤数和运营删除数。
查询与过滤:支持根据不同条件(如时间、评分等)对评论进行查询,以及设置过滤条件,筛选出需要进一步处理的评论。
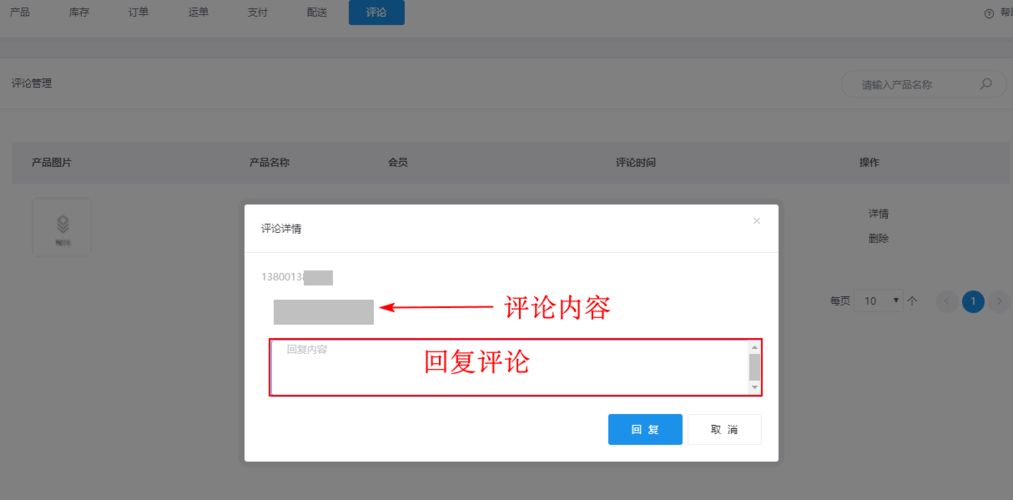
运营点赞与删除:允许运营团队对评论进行点赞提升曝光率,或删除不当评论以维护讨论环境。
5、反馈与迭代优化
系统性能监测:定期检查内容过滤系统的性能,包括准确率、召回率等指标。
规则更新与模型训练:根据监测结果和用户反馈,更新过滤规则或重新训练机器学习模型,不断优化过滤效果。
电商评论内容过滤系统的更新评论是一个涉及多个步骤和技术的过程,旨在提高评论质量,促进健康的消费讨论环境,通过上述各个关键步骤的实施,可以有效地管理和监控电商平台上的用户评论,为消费者和商家提供更有价值的信息。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/787337.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复