


在机器学习领域,Python凭借其强大的库支持和简洁的语法,成为了实现端到端机器学习场景的首选语言,本文将深入探讨如何利用Python进行机器学习项目的全过程,从数据预处理到模型训练,再到模型评估和应用。
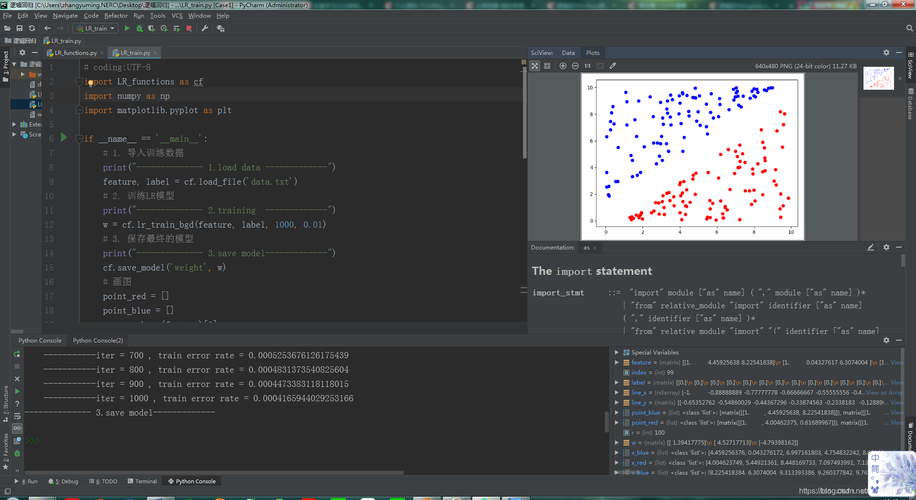

数据预处理
数据预处理是机器学习项目的第一步,它直接影响到模型的性能,在Python中,常用的数据预处理库包括NumPy、Pandas和Scikitlearn,使用Pandas可以方便地处理缺失值、异常值和数据格式化问题,通过这些工具,可以有效地清洗和准备数据,为后续的模型训练打下良好的基础。
模型选择
根据不同的问题类型(如分类、回归或聚类),选择合适的机器学习模型至关重要,Scikitlearn库提供了广泛的模型选择,包括决策树、随机森林、支持向量机等,选择合适的模型需要考虑数据的特征和问题的需求,通常通过交叉验证等方法来评估不同模型的表现。
模型训练与调优
在模型选定后,接下来是模型的训练和参数调优,这一步骤通常使用网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)来找到最优的参数组合,这些技术可以帮助自动化调整过程,寻找最佳的模型配置,从而提高模型的准确性和泛化能力。
模型评估
模型训练完成后,需要对模型的性能进行评估,这通常涉及到诸如准确率、召回率、F1分数和ROC曲线等多种评估指标,Scikitlearn提供了一系列评估函数,如classification_report和confusion_matrix,帮助研究者全面理解模型的表现。
模型部署
模型需要被部署到生产环境中,以解决实际问题,Python的Flask或Django框架常用于构建API,使模型能够接收输入并返回预测结果,模型可以使用Pickle或Joblib进行序列化保存,以便在不同的应用中重复使用。
项目实例
考虑到理论与实践的结合,参与或创建实际项目是学习的重要组成部分。《机器学习项目实战 10例》这样的资源提供了多个入门级项目,涵盖了从原理到源码的完整过程,通过这些项目,初学者可以实际操作每一个步骤,加深对机器学习流程的理解。
相关问答FAQs
Q1: 如何处理机器学习中的不平衡数据集?
Q1回答:不平衡数据集是指在分类问题中,某一类的样本数量远多于其他类,处理这一问题的常用策略包括重采样(过采样少数类或欠采样多数类)、使用集成学习方法如随机森林,或采用特定的算法比如集合学习,选择合适的评估指标,如AUCROC而不是简单准确率,也是关键。
Q2: 模型出现过拟合时应如何调整?
Q2回答:过拟合发生在模型在训练数据上表现优异但在未见数据上表现差的情况,应对策略包括引入正则化项(如L1和L2正则化),增加数据的多样性,使用交叉验证,或减少模型复杂度,采用 dropout 技术在深度学习模型中也是防止过拟合的有效手段。
Python在实现端到端机器学习解决方案中展示了其灵活性和强大功能,从数据处理到模型部署,Python的丰富生态系统为机器学习项目提供了全方位的支持,通过参与实际项目,学习者不仅可以掌握理论知识,还能获得宝贵的实践经验,这对于深入理解和有效应用机器学习技术至关重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/785928.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复