


在当今的数据驱动时代,机器学习技术已经成为了企业从海量数据中提取有价值信息的关键工具,Python作为数据科学和机器学习的首选编程语言,其丰富的库和框架,如ScikitLearn、TensorFlow等,提供了强大的支持,本文将深入探讨如何利用Python及其库实现端到端的机器学习项目,确保内容的准确性和全面性,同时保持逻辑的清晰性。

机器学习基础
1、背景介绍
问题的由来:在数据驱动的世界中,企业和组织面临从庞大数据集中提取有用信息的挑战,机器学习技术,尤其是基于Python的解决方案,为这一挑战提供了有效的解决途径。
Python的优势:Python因其简洁的语法、强大的库支持和广泛的社区,成为了数据科学和机器学习领域的首选语言。
2、核心库
ScikitLearn:作为一个提供一系列机器学习算法的库,ScikitLearn是实现端到端机器学习项目的重要工具。
TensorFlow:作为一个端到端的机器学习平台,TensorFlow不仅支持复杂的模型创建,还允许数据的灵活流动,其核心概念“tensor”和“flow”分别代表多维数组和数据的流动。
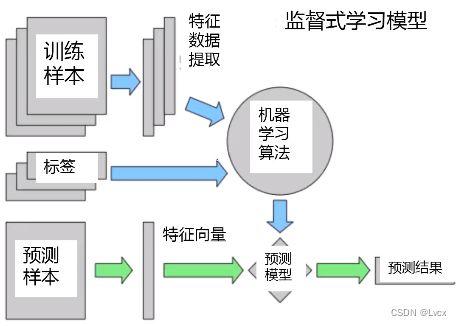
3、端到端机器学习流程
数据准备:包括数据的收集、清洗和预处理,确保数据质量和可用性。
模型选择:根据问题类型选择合适的机器学习模型,如分类、回归或聚类等。
训练与评估:使用训练数据集训练模型,并通过验证集和测试集评估模型性能。
模型优化:根据评估结果调整模型参数,进行特征工程等优化措施。
模型部署:将训练好的模型部署到生产环境,实现自动化预测和分析。
4、实战指南的重要性

理论与实践结合:虽然市面上有许多关于深度学习基础的介绍材料,但提供端到端机器学习项目实施的简洁文章却不多见。
案例分析:通过具体案例的分析,可以帮助读者更好地理解端到端机器学习项目的各个环节。
5、端到端学习的优点与挑战
优点:端到端机器学习可以自动化整个机器学习流程,提高模型性能。
挑战:尽管强大,但端到端机器学习也存在一些缺点,如模型的可解释性降低,对数据质量的要求更高等。
高级应用与优化策略
1、高级模型训练技巧
超参数调优:使用网格搜索、随机搜索或贝叶斯优化方法寻找最优的超参数组合。
集成学习:通过集成多个模型的预测来提高整体性能,常见的方法有bagging、boosting和stacking。
2、模型评估与选择
交叉验证:使用交叉验证来评估模型的泛化能力,避免过拟合。
性能指标:根据问题类型选择合适的性能指标,如准确率、召回率、F1分数等。
3、模型持久化与部署
模型保存:使用Python的pickle库或模型自带的保存函数来持久化训练好的模型。
模型服务:将模型部署到Web服务或云平台,实现API调用,便于实际应用。
相关问答FAQs
Q1: 如何处理不平衡数据集?
答案:不平衡数据集是指在分类问题中,某些类别的样本数量远少于其他类别,处理不平衡数据集的策略包括重采样(过采样少数类或欠采样多数类)、使用平衡的评估指标(如F1分数、AUCROC曲线等),以及尝试合成少数过采样技术(SMOTE)等方法。
Q2: 如何提高机器学习模型的可解释性?
答案:提高模型可解释性的方法包括使用简单的模型(如线性回归、决策树等)、特征重要性评估、局部可解释的模型无关解释(LIME)和模型特定方法(如SHAP值),适当的数据可视化和模型结果的直观呈现也有助于提高可解释性。
归纳而言,Python及其丰富的库和框架为端到端的机器学习项目提供了强大的支持,通过上述的详细步骤和策略,可以有效地实施和管理一个完整的机器学习项目,从而在数据驱动的世界中占据优势。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/785676.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复