


在当今的数据驱动时代,机器学习已经成为了技术革新和业务优化的关键驱动力,Python,作为一门广受欢迎的编程语言,凭借着其强大的库支持、简洁的语法以及庞大的社区资源,成为了机器学习领域的首选工具之一,Sklearn、KNN算法等是机器学习中常用的python代码,下面将深入探讨Python在机器学习中的应用,从基础环境搭建到项目实施的完整流程,旨在帮助读者构建一个清晰、全面的机器学习知识体系,具体分析如下:

1、环境搭建与基础语法
Python环境的配置:进入机器学习世界的第一步是配置Python环境,这一过程涉及到Python的安装、IDE选择以及必要库的管理,Anaconda是一个广泛推荐的Python发行版,它简化了库管理过程,使得环境搭建变得迅速且高效。
Python基础语法:掌握Python的基础语法对于机器学习项目的开展至关重要,数据类型、控制结构、函数以及面向对象编程等基本概念构成了Python编程的基石。
2、数据处理与可视化
数据清理和格式化:在机器学习项目中,数据的准备过程占据了大部分时间,Pandas库提供了丰富的数据处理功能,可以方便地进行数据清洗、转换以及缺失值处理等工作。
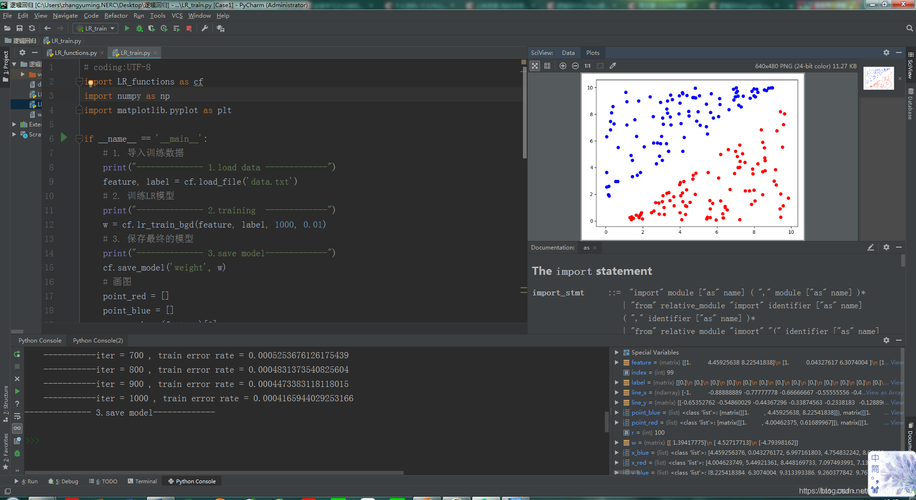
探索性数据分析:利用Matplotlib和Seaborn等库,可以通过绘制图表来探索数据的特性,比如分布、相关性等,这对于后续的特征工程和模型选择具有重要意义。
3、机器学习库与算法应用
ScikitLearn库:作为Python中最流行的机器学习库,ScikitLearn提供了广泛的监督学习和非监督学习算法,如分类、回归、聚类等,其清晰的文档和丰富的示例对初学者特别友好。
KNN分类算法:k近邻(KNN)算法简单易懂,通过测量不同特征值之间的距离进行分类,适用于初始阶段的原型开发和实验。
4、特征工程与模型优化
特征工程:特征工程包括特征的选择、转换和创造,对于提高模型的性能至关重要,通过PolynomialFeatures可以创建多项式特征,增加模型的复杂性以提高其预测能力。
模型微调:超参数调整是机器学习中的一个关键环节,GridSearchCV和RandomizedSearchCV等工具可以帮助我们遍历多种参数组合,寻找最优的模型设置。
5、项目实施与评估
项目流程:一个完整的机器学习项目流程包括数据准备、模型训练、评估和部署四个阶段,每个阶段都需要严谨的设计和执行,以确保模型的可靠性和有效性。
性能评估:使用适当的性能指标对模型进行评估非常重要,分类问题常用精确度、召回率和F1分数,而回归问题可能会考虑均方误差和R²值。
在以上基础上,可以进一步讨论几个相关的知识点和建议,以加深理解和扩展视野。
成功的机器学习项目不仅需要良好的编程实践,还要求对于特定领域有深入的理解,有效地利用业务知识来指导特征选择和模型选择,往往能够达到更好的效果。
随着模型复杂度的增加,过拟合成为常见问题,采用交叉验证等技术可以减少过拟合的风险,提高模型的泛化能力。
随着项目规模的扩大,模型的可解释性和部署的便利性变得越来越重要,选择适合问题的模型,并考虑到未来可能的扩展和维护工作,是非常必要的。
除了ScikitLearn之外,还有其他诸如TensorFlow和PyTorch等深度学习库,它们在处理大规模数据集和复杂模型时展现出不同的优势,了解这些库的使用场景和优缺点,有助于在面对具体问题时做出更合适的技术选择。
从Python环境的搭建到机器学习项目的完整实施,每一步都体现了Python在数据处理、模型构建和算法应用方面的卓越能力,通过精心设计的特征工程和细致的模型调优,可以充分利用Python及其强大库的功能,解决各种复杂的数据科学问题,不断探索新的工具和方法,与时俱进地更新知识储备,也是每一位数据科学工作者的必修课。
FAQs
Q1: Python中的ScikitLearn与其他机器学习库相比有什么优势?
Q1回答:ScikitLearn的优势在于它为数据挖掘和数据分析提供了一套完整的解决方案,包括数据预处理、模型选择、模型训练和模型评估等,其拥有着丰富的机器学习算法库,并且集成了众多便捷的数据处理工具,ScikitLearn有着非常活跃的社区和详尽的文档支持,这为初学者和专业人士提供了极大的便利。
Q2: 如何避免机器学习中的过拟合问题?
Q2回答:避免过拟合的方法有多种,可以通过增加数据集的规模来减少过拟合,因为更多的数据能够帮助模型学习到更加通用的模式,可以使用正则化技术如L1、L2正则化来限制模型复杂度,交叉验证也是一个有效的策略,它确保了模型在不同数据集上的表现一致性,集成学习方法如随机森林也能够降低过拟合风险,因为它们结合了多个模型的预测结果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/783897.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复