


1、Distinct性能优化重要性

查询中DISTINCT操作用于返回唯一值,尤其在处理大量数据时,其性能对整体查询效率影响显著,在大型数据库如user_access_xx_xx表中,不优化的DISTINCT操作可能导致查询效率低下,进而影响数据库应用的性能表现。
2、Distinct性能优化基本方法
使用LIMIT关键字可以限制DISTINCT查询返回的行数,适用于结果集非常大的情况,通过减少返回的数据量来提升查询速度,在统计某个表的独立访问量时,如果只关心大概的数量级,就可以使用LIMIT来快速得到估算值。
索引是加速数据库查询的重要手段,合理使用索引可以显著提高DISTINCT操作的性能,索引能够减少检索的数据量,特别是对于经常需要进行DISTINCT操作的列,创建索引可以有效缩短查询时间。
当数据集较大,一次性执行DISTINCT操作可能引起性能问题时,分块技术可以将数据分成小块分别处理,这种分而治之的策略可以减少单次操作的数据量,改善响应时间。
3、Distinct与Group By区别
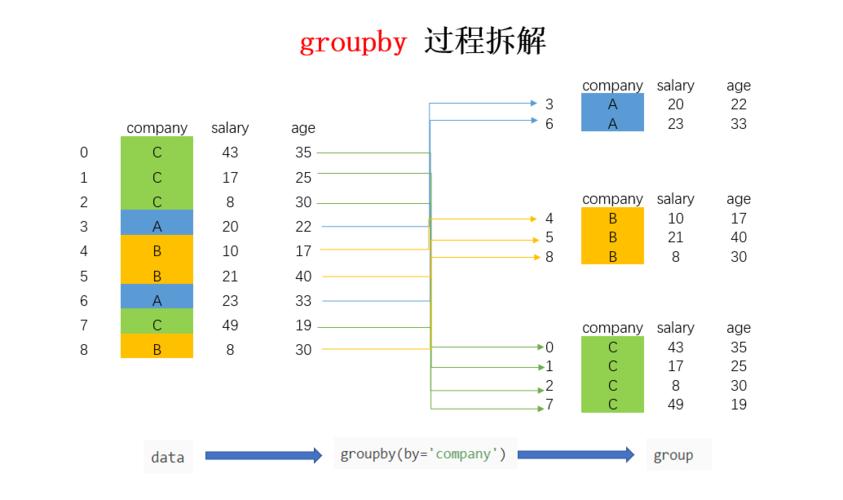
DISTINCT和GROUP BY虽然都能实现数据的去重,但它们的应用场景和执行机制有所不同,DISTINCT主要用于去除重复行,返回唯一的记录集合;GROUP BY则是用来进行分组,并在每个分组上进行聚合计算,适用于更复杂的数据统计需求。

在执行方式上,DISTINCT需要遍历整个表进行两两比较,而GROUP BY则类似先建立索引再利用索引进行查询,在面对大数据量时,GROUP BY通常比DISTINCT具有更好的性能表现。
4、Distinct与Group By性能对比
在MySQL 8.0之前的版本中,DISTINCT和GROUP BY的性能差异主要源于是否使用了索引,无索引的情况下,GROUP BY往往因为其索引优化而表现得更加高效。
自MySQL 8.0版本起,无论是否使用索引,GROUP BY的性能都得到了显著提升,这使得在大数据处理时,GROUP BY成为了更受欢迎的选择。
5、相关FAQs
如何在实际场景中选择合适的去重方法?
在选择去重方法时,首先应考虑查询的需求,如果目的是简单的去除重复行并获取唯一值,DISTINCT是直接且有效的选择,若涉及到复杂的数据分析,如分组统计和聚合计算,GROUP BY提供了更多的灵活性和优化空间,考虑到性能因素,当处理的数据量较大时,倾向于使用GROUP BY,特别是在新版MySQL中其性能优势更为明显。
为什么在大数据量下GROUP BY通常比DISTINCT快?
在处理大数据量时,GROUP BY的操作逻辑使其能够更好地利用索引结构,类似于先建立索引再进行查询,这减少了必要的数据比较次数,相比之下,DISTINCT需要遍历整个表进行数据比较,这在数据量大时会导致更多的计算和IO操作,从而影响性能,在数据量大的情况下,GROUP BY通常能提供更快的查询速度。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/783825.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复