


在当今数据驱动的时代,机器学习作为人工智能的一个重要分支,已经在多个领域中显示出其强大的数据处理和预测能力,Python作为机器学习的首选语言之一,拥有丰富的库和框架支持,使得构建端到端的机器学习项目变得可行与高效,本文将通过详细的步骤和实例,指导读者如何使用ScikitLearn构建端到端的机器学习项目,我们不仅将覆盖算法选择、数据预处理、模型训练、评估及优化等多个方面,还将探讨如何利用ScikitLearn解决真实世界中的问题,并提供一些建议和最佳实践,以帮助读者构建更加高效和可靠的机器学习系统。


基础知识准备
在开始一个机器学习项目之前,了解其核心概念和相关技术是非常重要的,机器学习通常包括监督学习、非监督学习和强化学习等类型,每种类型下又有多种算法可供选择,ScikitLearn库提供了从KNN、朴素贝叶斯到决策树和随机森林等多种算法,选择合适的算法需要根据具体问题的需求、数据的特性以及预期的输出类型来决定。
环境设置与数据收集
确保开发环境的正确设置是成功实施机器学习项目的第一步,安装必要的Python库,如Numpy、PIL和ScikitLearn,为数据处理和模型构建提供支持,环境的准备可以通过Anaconda等集成环境来简化,数据收集和初步分析也是重要的初步步骤,它决定了后续处理的方向和方法。
数据预处理与特征工程
数据预处理是机器学习中非常关键的一步,它直接影响到模型的性能和效果,常见的预处理步骤包括数据清洗、缺失值处理、归一化或标准化等,特征工程则涉及到如何选择、转换和创建特征,以便更好地表示数据,提高模型的预测能力。
模型选择与训练
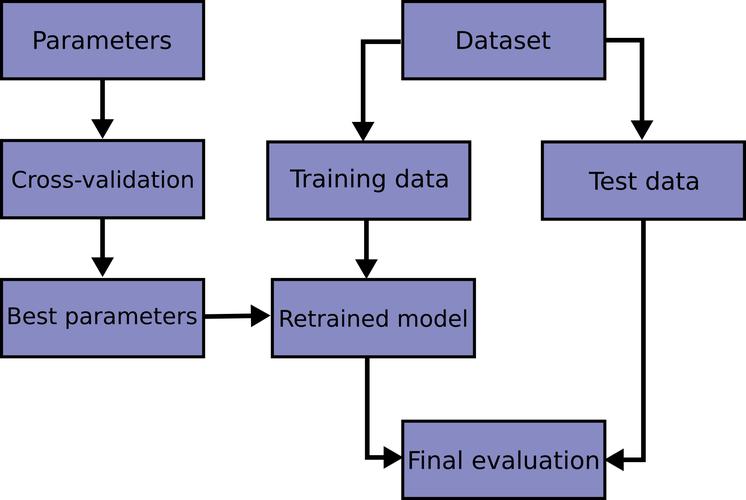
根据问题的类型(如分类、回归或聚类),选择合适的机器学习模型进行训练,ScikitLearn提供了简洁的API来快速构建和训练模型,使用sklearn.ensemble.RandomForestClassifier可以容易地实现随机森林分类器的训练,模型训练的过程中,还需要注意超参数的调整,这通常通过网格搜索或随机搜索来实现模型的优化。
模型评估与优化
模型的评估关注模型在未见数据上的表现,常用的评估指标包括准确率、召回率、F1分数等,ScikitLearn提供了cross_val_score等函数来支持交叉验证,帮助开发者获取更稳健的模型评估结果,模型的优化不仅包括参数调整,还可能涉及回到特征工程步骤进一步改进特征提取。
实例应用与部署
理论与实践相结合是掌握机器学习的关键,通过实际案例如文本分类、图像识别等,可以让学习者更好地理解每个步骤的重要性及其在实际问题中的应用,完成模型训练和测试后,将其部署到生产环境中,使用Flask或Django等Python Web框架,可以使模型易于访问和使用。
上文归纳与建议
构建端到端的机器学习项目是一个综合性强、实践性高的任务,通过Python及其丰富的库,如ScikitLearn,可以有效地进行数据处理、模型构建及评估,成功的机器学习项目不仅需要技术的支持,还需要对问题的深入理解和严谨的实验设计。

Q1: 如何选择合适的机器学习算法?
Q2: 如何处理数据集中存在的缺失值?
Q1: 选择合适的机器学习算法依赖于问题的类型(如分类、回归等),数据的大小和质量,以及预期的模型性能,可以先从简单的模型开始,如逻辑回归或决策树,逐步尝试更复杂的模型如随机森林或神经网络,并通过交叉验证来评估不同模型的性能。
Q2: 处理缺失值的方法包括删除含有缺失值的行/列、使用均值或中位数填充、预测模型填充等,选择哪种方法取决于数据缺失的程度和性质,以及数据对模型的重要性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/783773.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复