

在统计学和机器学习领域,多重线性回归方法是一种重要的工具,用于研究一个响应变量与多个自变量之间的线性关系,这种方法是两变量线性回归的扩展,并且在模型估计、解释、评价及诊断等方面与其基本相同,本文将详细探讨多重线性回归的基本概念、模型建立、假设检验以及应用实例,并解答一些常见问题。
多重线性回归分析(Multiple Linear Regression, MLR)是研究一个因变量与多个自变量间线性因果关系的统计方法,它不仅要求因变量与所有自变量存在线性关系,还要求因变量与每一个自变量之间也存在线性关系,这种分析方法可以有效地揭示多个因素对某一结果的综合影响。
在多重线性回归中,模型的一般形式可以表示为:Y = β0 + β1X1 + β2X2 + … + βmXm + e,Y是因变量,X1到Xm是自变量,β0是常数项(截距),β1到βm是偏回归系数,e是随机误差(即残差),这一模型说明了在其他自变量不变的情况下,某一自变量每变化一个单位,因变量Y的平均变化量。
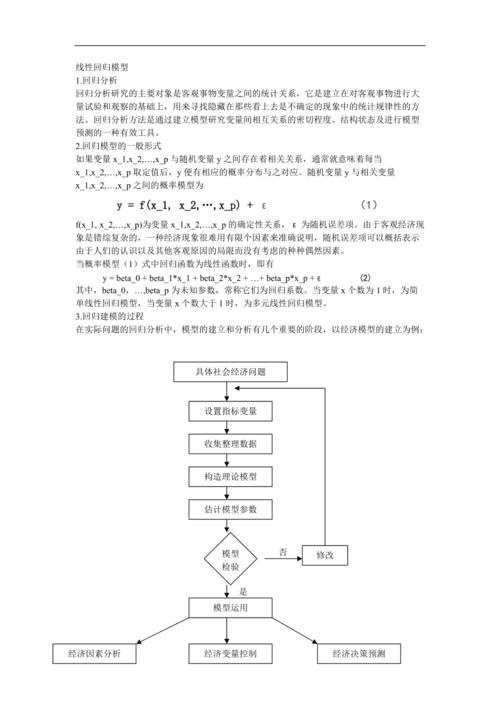
进行多重线性回归分析时,需要首先确保数据满足一定的条件,这些条件包括:因变量与每个自变量之间必须存在线性关系;各观测值之间相互独立;残差(随机误差)应服从均值为0的正态分布,且具有常数方差(同方差性),自变量之间不应存在高度相关性,即多重共线性的问题。
在实际应用中,可以通过散点图等方式初步判断变量间是否存在线性关系,进一步地,可以使用方差分析(ANOVA)等统计方法来检验模型的整体显著性,以及t检验来检验各个自变量的系数是否显著不为零,这些都是评估多重线性回归模型拟合优度和显著性的重要步骤。
在经济学研究中,一个研究者可能对家庭消费支出(因变量Y)与家庭收入、教育水平及年龄(自变量X1、X2和X3)之间的关系感兴趣,通过收集相关数据并建立多重线性回归模型,研究者可以量化这些因素对消费支出的具体影响。
在构建和应用多重线性回归模型时,需要注意的几个关键问题包括:模型的选择、自变量的筛选、以及模型的诊断,模型选择涉及确定哪些变量应该包含在模型中;自变量的筛选则需要避免不必要的变量导致的过拟合问题;模型诊断则是检查模型是否满足线性、独立和同方差的假设。
对于初学者而言,理解和运用多重线性回归可能会遇到一些困难,如何选择合适的自变量?这通常需要基于理论或以往的研究经验来决定,如何处理违反假设的情况(如异方差性或自相关的存在)也是一大挑战,可能需要采用加权最小二乘法或广义最小二乘法等更复杂的统计技术来解决。

在应用多重线性回归时,研究者应当注意模型的解释不能超出数据本身的范围,即避免过度外推,模型的结果需要以清晰、准确的方式呈现,以便其他研究者或决策者能够正确理解和应用这些发现。
FAQs
多重线性回归中的“多重”是什么意思?
“多重”指的是模型中包括多个自变量,这与简单线性回归不同,后者只涉及一个自变量,多重线性回归允许研究者同时考虑多个因素对因变量的影响。
如果数据违反了多重线性回归的假设怎么办?
如果数据违反了多重线性回归的基本假设,如存在异方差性或自相关等问题,可以考虑使用加权最小二乘法或广义最小二乘法等方法进行处理,也可以对数据进行变换(如对数转换),或引入额外的解释变量来改善模型的拟合效果。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/782452.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复